2.0、理解DexStringId
2.0、解析DexStringId
3.0、理解DexTypeId
3.0、解析DexTypeId
4.0、理解DexFieldId
4.0、解析DexFieldId
5、DexMethodId
5.0、理解DexMethodId
5.0、解析DexMethodId
6.0、理解DexProtoId
6.0、解析DexProtoId
7.0、理解DexClassDef
7.0、理解DexClassDef
8.待续....狗命要紧
当多个class文件被编译到一个dex文件是,他们会用到link_size和link_off,通常为0
格式:

图只是指示性的用两个字节表示。编码的每个字节有效部分只有低7bits,每个字节的最高bit用来指示是否是最后一个字节。
非最高字节的bit7为0
最高字节的bit7为1
将leb128编码的数字转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
比如:
LEB128编码的0x02b0 ---> 转换后的数字0x0130
转换过程:
0x02b0 ---> 0000 0010 1011 0000 -->去除最高位--> 000 0010 011 0000 -->按4bits重排 --> 00 0001 0011 0000 --> 0x130
引用 https://blog.csdn.net/Roland_Sun/article/details/46708061
同时 还有2个很重要的字段在DexHeader中typeIdsSize和typeIdsOff 同样代表类型的偏移和大小.
先来分析第一个type:
得知第一个type所在位置是 00 00 38 FC
010
得到的值是 0x19F
根据描述 /* 指向string_ids的索引 */ 知道这个值是字符串偏移的索引
0x19F = 415
恰好是第一个类型的值 : B byte
如此就分析出第一个类型的位置和来源了
010:

总结:
那么来到 824C
之前分析过type 这次 分析结构中的 type_idx
上图可见 type_idx的地址的值内容为 0x1D 也就是 29
可以看到 他们的值是一致的!
另外2个原理一直,可以自行分析

截图截多了!不好意思!
比较麻烦的是取值的过程需要通过其他属性来取值
输出

010
描述的比较清晰
输出:
010
具体结构
010:

010:

代码写的比较乱,在这次学习中收获挺多的..
各位大神看完了有什么错的那啥,,轻点,,
最近在学习dex文件,把学习的过程记录一下!有什么不对的地方还各位多多指点,感激不尽!
目录:
1、DexHeader
1.0、理解DexHeader
1.1、解析DexHeader
2、 DexStringId
2.0、理解DexStringId
2.0、解析DexStringId
3、DexTypeId
3.0、理解DexTypeId
3.0、解析DexTypeId
4、DexFieldId
4.0、理解DexFieldId
4.0、解析DexFieldId
5、DexMethodId
5.0、理解DexMethodId
5.0、解析DexMethodId
6、DexProtoId
6.0、理解DexProtoId
6.0、解析DexProtoId
7、DexClassDef
7.0、理解DexClassDef
7.0、理解DexClassDef
8、DexLink
随便拖入一个Dex文件到010,运行DEXTemplate.bt,就能看到下图中的Dex的结果
接下开始逐个分析Dex文件结构
我用是的android-6.0.0_r1的源码中DexFile.h
/*
* Structure representing a DEX file.
*
* Code should regard DexFile as opaque, using the API calls provided here
* to access specific structures.
*/
struct DexFile {
directly-mapped "opt" header */
//const DexOptHeader* pOptHeader;
/*
对应关系如下
DexHeader* pHeader ---->struct header_item dex_header
DexStringId* pStringIds---->struct string_id_list dex_string_ids
DexTypeId* pTypeIds ---->struct type_id_list dex_type_ids
DexFieldId* pFieldIds ---->struct field_id_list dex_field_ids
DexMethodId* pMethodIds---->struct method_id_list dex_method_ids
DexProtoId* pProtoIds ---->struct proto_id_list dex_proto_ids
DexClassDef* pClassDefs---->struct class_def_item_list dex_class_defs
DexLink* pLinkData ---->struct map_list_type dex_map_list
*/
/* pointers to directly-mapped structs and arrays in base DEX */
DexHeader* pHeader; //DEX 文件头,记录了一些当前文件的信息以及其他数据结构在文件中的偏移量
DexStringId* pStringIds; //数组,元素类型为string_id_item,存储字符串相关的信息
DexTypeId* pTypeIds; //数组,存储类型相关的信息
DexFieldId* pFieldIds; //数组,存储成员变量信息,包括变量名和类型等
DexMethodId* pMethodIds; //数组,存储成员函数信息包括函数名 参数和返回值类型
DexProtoId* pProtoIds; //数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表
DexClassDef* pClassDefs; //数组,存储类的信息
DexLink* pLinkData; //Dex文件重要的数据内容都存在data区域内,一些数据结构会通过如 xx_off这样的成员变量只想文件的某个位置,从该位置开始,存储了对应的数据结构的内容,而xx_off的位置一般落在data区域内
/*
* These are mapped out of the "auxillary" section, and may not be
* included in the file.
*/
const DexClassLookup* pClassLookup;
const void* pRegisterMapPool; // RegisterMapClassPool
/* points to start of DEX file data */
const u1* baseAddr;
/* track memory overhead for auxillary structures */
int overhead;
/* additional app-specific data structures associated with the DEX */
//void* auxData;
};
/*
* Structure representing a DEX file.
*
* Code should regard DexFile as opaque, using the API calls provided here
* to access specific structures.
*/
struct DexFile {
directly-mapped "opt" header */
//const DexOptHeader* pOptHeader;
/*
对应关系如下
DexHeader* pHeader ---->struct header_item dex_header
DexStringId* pStringIds---->struct string_id_list dex_string_ids
DexTypeId* pTypeIds ---->struct type_id_list dex_type_ids
DexFieldId* pFieldIds ---->struct field_id_list dex_field_ids
DexMethodId* pMethodIds---->struct method_id_list dex_method_ids
DexProtoId* pProtoIds ---->struct proto_id_list dex_proto_ids
DexClassDef* pClassDefs---->struct class_def_item_list dex_class_defs
DexLink* pLinkData ---->struct map_list_type dex_map_list
*/
/* pointers to directly-mapped structs and arrays in base DEX */
DexHeader* pHeader; //DEX 文件头,记录了一些当前文件的信息以及其他数据结构在文件中的偏移量
DexStringId* pStringIds; //数组,元素类型为string_id_item,存储字符串相关的信息
DexTypeId* pTypeIds; //数组,存储类型相关的信息
DexFieldId* pFieldIds; //数组,存储成员变量信息,包括变量名和类型等
DexMethodId* pMethodIds; //数组,存储成员函数信息包括函数名 参数和返回值类型
DexProtoId* pProtoIds; //数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表
DexClassDef* pClassDefs; //数组,存储类的信息
DexLink* pLinkData; //Dex文件重要的数据内容都存在data区域内,一些数据结构会通过如 xx_off这样的成员变量只想文件的某个位置,从该位置开始,存储了对应的数据结构的内容,而xx_off的位置一般落在data区域内
/*
* These are mapped out of the "auxillary" section, and may not be
* included in the file.
*/
const DexClassLookup* pClassLookup;
const void* pRegisterMapPool; // RegisterMapClassPool
/* points to start of DEX file data */
const u1* baseAddr;
/* track memory overhead for auxillary structures */
int overhead;
/* additional app-specific data structures associated with the DEX */
//void* auxData;
};
通过上面的源码的注释知道了各个结构的大意与010的对应的关系,但是还不清楚这些结构的内部是什么样子的!
那么开始解析第一个结构 DexHeader:
/*
* Direct-mapped "header_item" struct.
*/
struct DexHeader {
u1 magic[8]; //取值必须是字符串 "dex\n035\0" 或者字节byte数组 {0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00}
u4 checksum; //文件内容的校验和,不包括magic和自己,主要用于检查文件是否损坏
u1 signature[kSHA1DigestLen]; //签名信息,不包括 magic\checksum和自己
u4 fileSize; //整个文件的长度,单位为字节,包括所有的内容
u4 headerSize; //默认是0x70个字节
u4 endianTag; //大小端标签,标准.dex文件为小端,此项一般固定为0x12345678常量
u4 linkSize; //链接数据的大小
u4 linkOff; //链接数据的偏移值
u4 mapOff; //map item的偏移地址,该item属于data区里的内容,值要大于等于dataOff的大小
u4 stringIdsSize; //DEX中用到的所有字符串内容的大小*
u4 stringIdsOff; //DEX中用到的所有字符串内容的偏移量
u4 typeIdsSize; //DEX中类型数据结构的大小
u4 typeIdsOff; //DEX中类型数据结构的偏移值
u4 protoIdsSize; //DEX中的元数据信息数据结构的大小
u4 protoIdsOff; //DEX中的元数据信息数据结构的偏移值
u4 fieldIdsSize; //DEX中字段信息数据结构的大小
u4 fieldIdsOff; //DEX中字段信息数据结构的偏移值
u4 methodIdsSize; //DEX中方法信息数据结构的大小
u4 methodIdsOff; //DEX中方法信息数据结构的偏移值
u4 classDefsSize; //DEX中的类信息数据结构的大小
u4 classDefsOff; //DEX中的类信息数据结构的偏移值
u4 dataSize; //DEX中数据区域的结构信息的大小
u4 dataOff; //DEX中数据区域的结构信息的偏移值
};
看010中对应的位置
u1 magic[8]; //取值必须是字符串 "dex\n035\0" 或者字节byte数组 {0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00} u1 magic[8]; //取值必须是字符串 "dex\n035\0" 或者字节byte数组 {0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00}下图选中magic时 会选中前八个字节magic[8] u1代表字节 [8] 则是8个字节
可以把magic看做dex文件的标识{0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00}
通过这个字段知道是该文件dex文件
它是一个u4 代表4个字节的内容,
u4 checksum; //文件内容的校验和,不包括magic和自己,主要用于检查文件是否损坏
u4 checksum; //文件内容的校验和,不包括magic和自己,主要用于检查文件是否损坏
signature[kSHA1DigestLen]了,signature字段用于检验dex文件,其实就是把整个dex文件用SHA-1签名得到的一个值。这里占用20个字节
u1 signature[kSHA1DigestLen]; //签名信息,不包括 magic\checksum和自己
kSHA1DigestLen:
/*
* 160-bit SHA-1 digest.
*/
enum { kSHA1DigestLen = 20,
kSHA1DigestOutputLen = kSHA1DigestLen*2 +1 };
fileSize:文件长度
u4 fileSize; //整个文件的长度,单位为字节,包括所有的内容
553820个字节大小
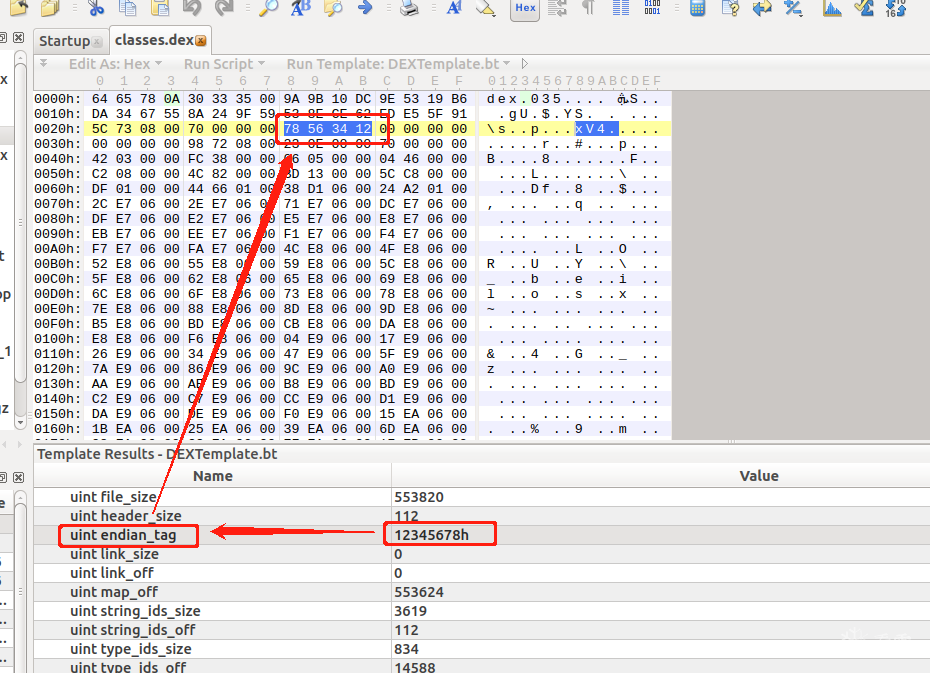
表示 DexHeader 头结构的大小,占用4个字节。这里可以看到它一共占用了112个字节,112对应的16进制数为70h
u4 headerSize; //默认是0x70个字节
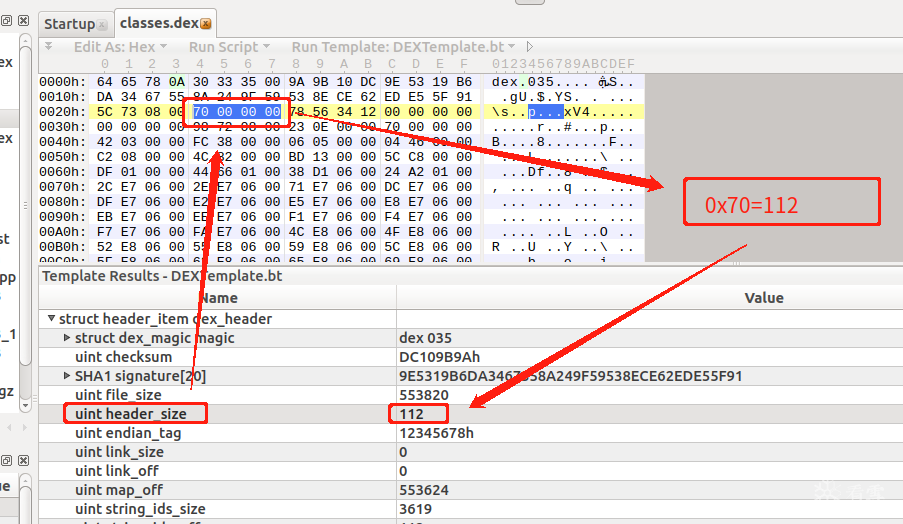
u4 endianTag; //大小端标签,标准.dex文件为小端,此项一般固定为0x12345678常量
0
当多个class文件被编译到一个dex文件是,他们会用到link_size和link_off,通常为0
u4 linkSize; //链接数据的大小
u4 linkOff; //链接数据的偏移值
mapOff字段了,它指定了 DexMapList 的文件偏移
u4 mapOff; //map item的偏移地址,该item属于data区里的内容,值要大于等于dataOff的大小
stringIdsSize代表全dex文件的字符串的个数
stringIdsOff 代表全dex文件的字符串的偏移
u4 stringIdsSize; //DEX中用到的所有字符串内容的大小*
u4 stringIdsOff; //DEX中用到的所有字符串内容的偏移量
有了这个知识 可以尝试分析第一个字符串
已经找到第一个字符串的偏移是6e72c
那么也就找到了 第一个字符串的值 虽然看不明显但确实如此
以上的2个问题会在解析中给出答案!
这指出了type类型的偏移和type的个数
u4 typeIdsSize; //DEX中类型数据结构的大小
u4 typeIdsOff; //DEX中类型数据结构的偏移值
略...
u4 protoIdsSize; //DEX中的元数据信息数据结构的大小
u4 protoIdsOff; //DEX中的元数据信息数据结构的偏移值
u4 fieldIdsSize; //DEX中字段信息数据结构的大小
u4 fieldIdsOff; //DEX中字段信息数据结构的偏移值
u4 methodIdsSize; //DEX中方法信息数据结构的大小
u4 methodIdsOff; //DEX中方法信息数据结构的偏移值
u4 classDefsSize; //DEX中的类信息数据结构的大小
u4 classDefsOff; //DEX中的类信息数据结构的偏移值
u4 dataSize; //DEX中数据区域的结构信息的大小
u4 dataOff; //DEX中数据区域的结构信息的偏移值
1.1、解析DexHeader
那么就开始动手写的代码来解析吧~~
用的Clion编译器
1.
首先 先写个一个读取文件的方法
char* Read_File(string file_Path) {
filebuf *pbuf;
ifstream filestr;
long size;
char *buffer;
// 要读入整个文件,必须采用二进制打开
filestr.open(file_Path, ios::binary);
// 获取filestr对应buffer对象的指针
pbuf = filestr.rdbuf();
// 调用buffer对象方法获取文件大小
size = pbuf->pubseekoff(0, ios::end, ios::in);
pbuf->pubseekpos(0, ios::in);
// 分配内存空间
buffer = new char[size];
// 获取文件内容
pbuf->sgetn(buffer, size);
filestr.close();
// 输出到标准输出
//cout.write (buffer,size);
// delete []buffer;
return buffer;
}
2.
main:
//得到文件内存地址指针
char* fp = Read_File("/home/zlq/baidunetdiskdownload/android/classes.dex");
//强转为DexFile指针
DexFile *dex = (DexFile*)&fp;
//解析struct header_item dex_header
Read_DexHeader(dex->pHeader);
3.
写的比较拙劣,,,,
/**
* 实现方法
* @param dexHeader
*/
void Read_DexHeader(DexHeader* dexHeader)
{
//struct header_item dex_header
printf("struct header_item dex_header\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t0x0");
printf("\t\t\t\t0x%x", (unsigned int)sizeof(DexHeader));
printf("\t\tDEX 文件头,记录了一些当前文件的信息以及其他数据结构在文件中的偏移量");
printf("\n\tmagic\t\t\t\t\t\t\t\t");
char* magic = (char*)dexHeader->magic;
while(*magic != '\0')
{
if(*magic != '\n')
{
printf("%c ",(*magic));
}
magic++;
}
printf("\t\t\t\t\t\t\t\t\t\t0x0\t\t\t\t0x%x\t\t\t取值必须是字符串 \"dex\\n035\\0\" 或者字节byte数组 {0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00}",
(unsigned int)sizeof(dexHeader->magic));
printf("\n\tchecksum\t\t\t\t\t\t\t0x%X\t\t\t\t\t\t\t\t\t\t\t0x%x\t\t\t\t0x%x\t\t\t文件内容的校验和,不包括magic和自己,主要用于检查文件是否损坏"
,dexHeader->checksum
,(unsigned int)sizeof(dexHeader->magic)
,(unsigned int)sizeof(dexHeader->checksum));
.... 略
输出
通过对比分析是一样的
这个比较简单,用结构指针接受一下就行了 只是输出有点麻烦
2、 DexStringId
2.0、理解DexStringId
DEX中所有的字符串存储在这里
DexStringId* pStringIds; //数组,元素类型为string_id_item,存储字符串相关的信息
进去看看此结构!
它只有一个字段,那么它是如何解析dex字符串呢?
/*
* Direct-mapped "string_id_item".
*/
struct DexStringId {
//用于指明 string_data_item 位置文件的位置
u4 stringDataOff; /* file offset to string_data_item */
};首先要知道的是它是一个数组类型,数组的大小取决于
DexHeader->stringIdsSize
那么就很好理解了,上面提示 一共 有3619个 字符串
解析主要靠DexHeader中的stringIdsSize和stringIdsOff来解析
2.0、解析DexStringId
又开始写代码了
void Read_DexStringId(char* fp) {
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct string_id_list dex_string_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->stringIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexStringId));
printf("\t\t\t数组,元素类型为string_id_item,存储字符串相关的信息");
//拿到字符串的偏移
int *p2 = (int*)(fp + dex->pHeader->stringIdsOff);
////stringIdsSize --> DEX中用到的所有字符串内容的大小
for (int i = 0; i < dex->pHeader->stringIdsSize; ++i) {
printf("\n\tstruct string_id_item string_id[%d]:",i);
// 文件首地址+字符串偏移就是字符串存放的位置的第一个数组
const u1* stringdata = (u1*)fp+*p2;
//解码
/*
* dex文件里采用了变长方式表示字符串长度。一个字符串的长度可能是一个字节(小于256)或者4个字节(1G大小以上)。字符串的长度大多数都是小于 256个字节,因此需要使用一种编码,既可以表示一个字节的长度,也可以表示4个字节的长度,并且1个字节的长度占绝大多数。能满足这种表示的编码方式有很多,但dex文件里采用的是uleb128方式。leb128编码是一种变长编码,每个字节采用7位来表达原来的数据,最高位用来表示是否有后继字节。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高位为 0 。每个 Byte 的其余 Bit 用来表示数据
*/
readUnsignedLeb128(&stringdata);
//转码后该字符串为 内存数据为 \0 时 则结束
while(*stringdata != '\0')
{
//换行
if((*stringdata) != '\a' && (*stringdata) != '\b' &&(*stringdata) != '\t' && (*stringdata) != '\n' && (*stringdata) != '\v' && (*stringdata) != '\r' && (*stringdata) != '\f' )
{
printf("%c",(*stringdata));
}
//printf("%c",(*stringdata));
stringdata++;
}
p2++;
}
}
其中一部分的输出:
010:
总结:
* dex->pHeader->stringIdsOff 存储了整个dex的字符串的偏移的首地址 是一个数组类型
* dex->pHeader->stringIdsSize 存储字符串的个数
* 字符串偏移指向的地址的内容通过 readUnsignedLeb128 解码 字符串的长度通过判断'\0' 即可
编码:
LEB128即"Little-Endian Base 128",基于128的小印第安序编码格式,是对任意有符号或者无符号整型数的可变长度的编码。
也即,用LEB128编码的正数,会根据数字的大小改变所占字节数。在android的.dex文件中,他只用来编码32bits的整型数。
格式:
图只是指示性的用两个字节表示。编码的每个字节有效部分只有低7bits,每个字节的最高bit用来指示是否是最后一个字节。
非最高字节的bit7为0
最高字节的bit7为1
将leb128编码的数字转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
比如:
LEB128编码的0x02b0 ---> 转换后的数字0x0130
转换过程:
0x02b0 ---> 0000 0010 1011 0000 -->去除最高位--> 000 0010 011 0000 -->按4bits重排 --> 00 0001 0011 0000 --> 0x130
引用 https://blog.csdn.net/Roland_Sun/article/details/46708061
3、DexTypeId
3.0、理解DexTypeId
* type_ids 区索引了 .dex 文件里的所有数据类型 ,包括 class 类型 ,数组类型(array types)和基本类型(primitive types) 。 本区域里的元素格式为type_ids_item
* type_ids_item 里面 descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串 。
DexTypeId* pTypeIds; //数组,存储类型相关的信息
看结构
他也是一个字段,且看如何分析它
注意是一个数组的类型
/*
* Direct-mapped "type_id_item".
*/
struct DexTypeId {
u4 descriptorIdx; /* 指向string_ids的索引 */
};
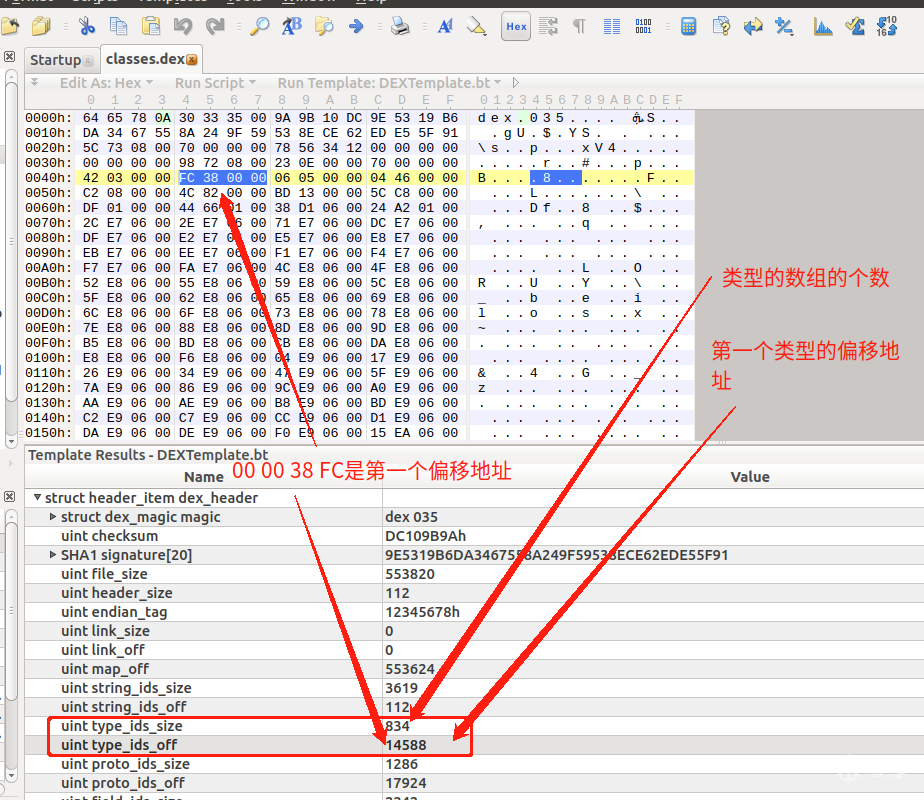
同时 还有2个很重要的字段在DexHeader中typeIdsSize和typeIdsOff 同样代表类型的偏移和大小.
先来分析第一个type:
得知第一个type所在位置是 00 00 38 FC
010
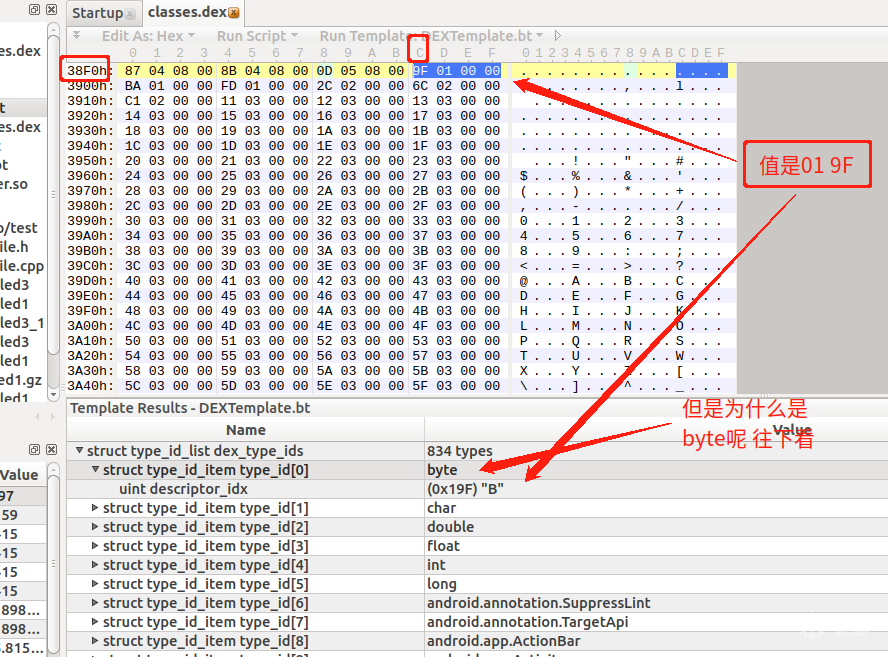
得到的值是 0x19F
根据描述 /* 指向string_ids的索引 */ 知道这个值是字符串偏移的索引
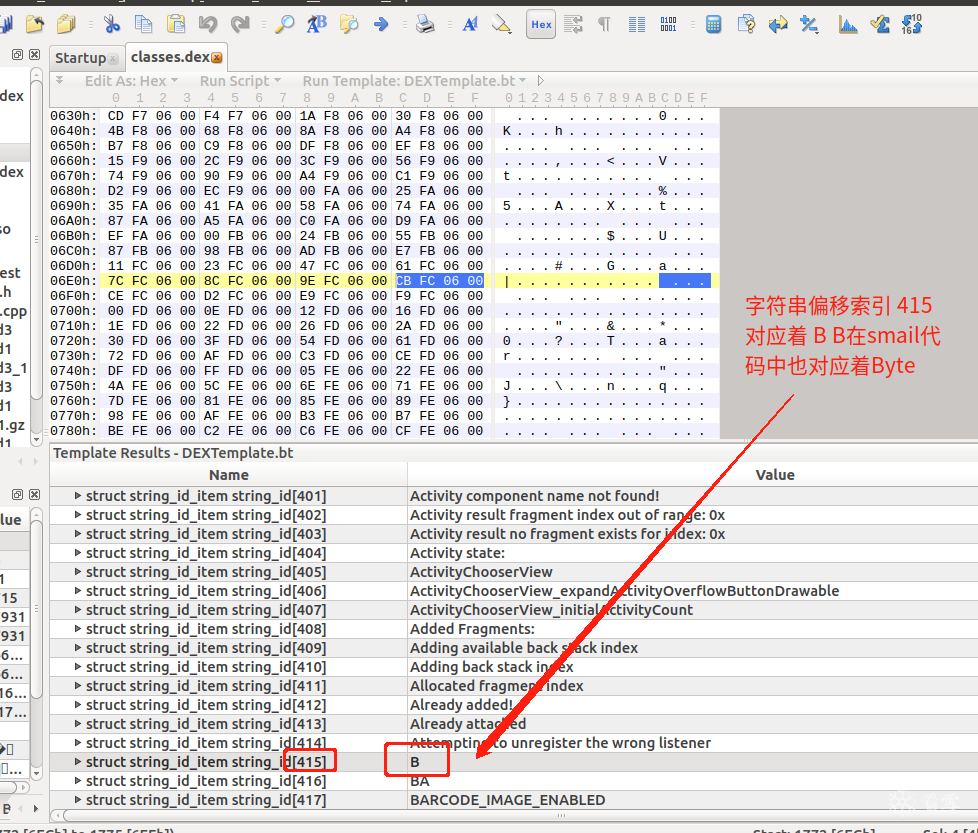
0x19F = 415
恰好是第一个类型的值 : B byte
如此就分析出第一个类型的位置和来源了
3.0、解析DexTypeId
又开始写代码:
void Read_DexTypeId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct struct type_id_list dex_type_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->typeIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexTypeId));
printf("\t\t\t数组,存储类型相关的信息\n");
//拿到类型的偏移
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
for (int i = 0; i < dex->pHeader->typeIdsSize; ++i) {
printf("\n\tstruct type_id_list dex_type_ids[%d]:",i);
//先拿到字符串的偏移
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
//再根据类型的偏移去寻找字符串
const u1* stringdata = (u1*)fp+stringIdsOff[(*typeIdsOff)];
//解码
readUnsignedLeb128(&stringdata);
while(*stringdata != '\0')
{
printf("%c",(*stringdata));
stringdata++;
}
//自加 获取下一个指针 int型指针自加 base += 1
typeIdsOff++;
}
}
输出:
010:
总结:
descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串
字符串指针[descriptor_idx地址内的值] = descriptor_idx值
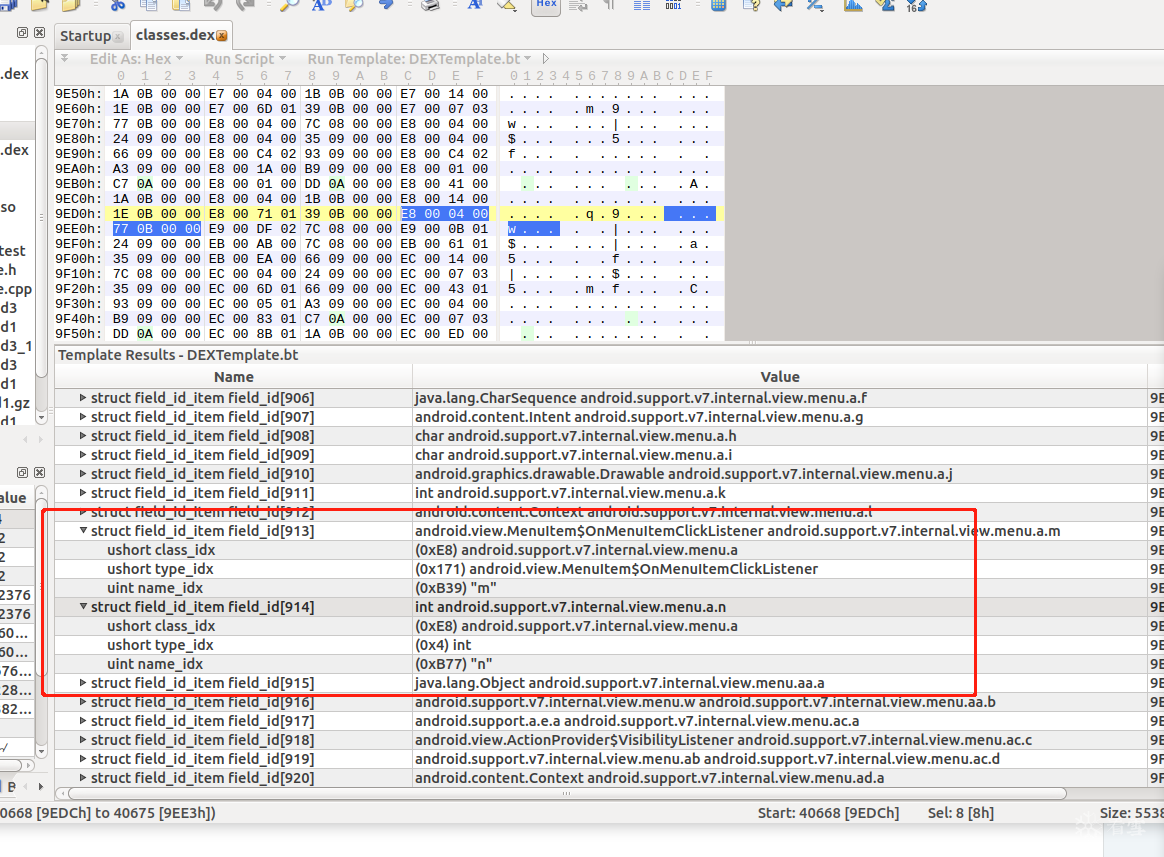
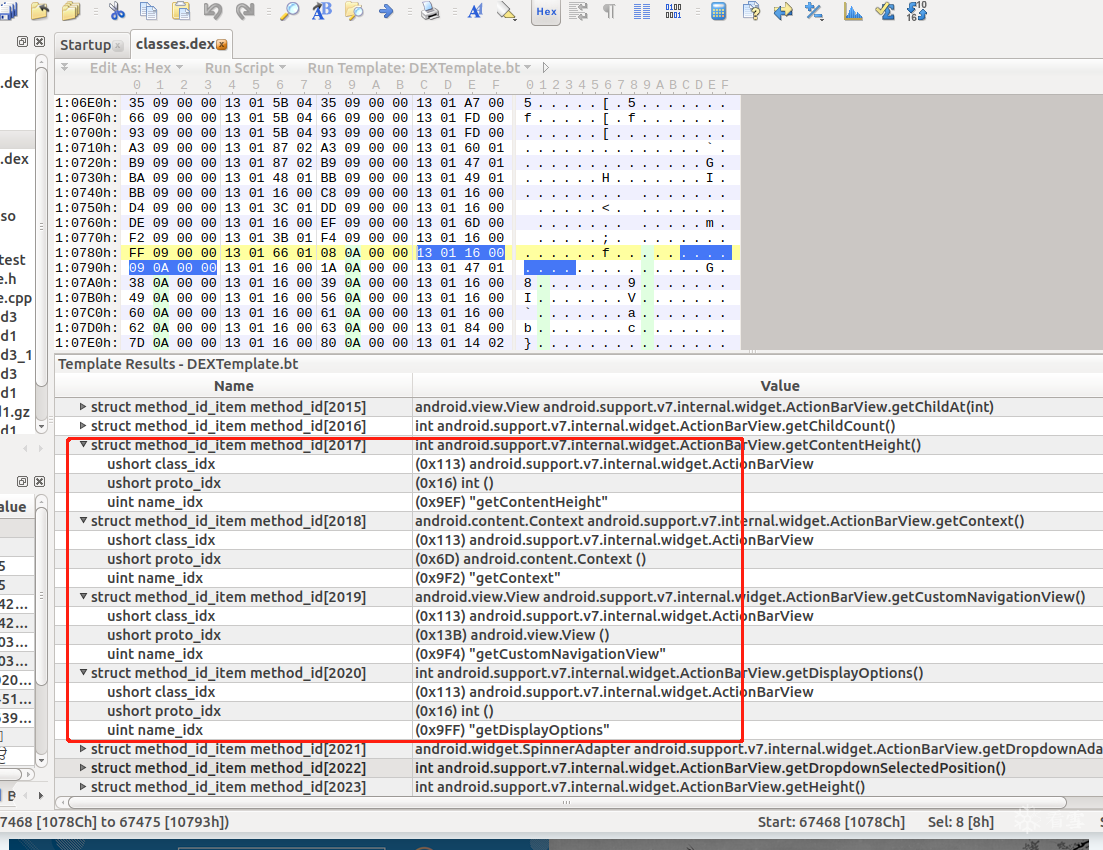
4、DexFieldId
4.0、理解DexFieldId
大意:
DexFieldId* pFieldIds; //数组,存储成员变量信息,包括变量名和类型等
具体结构:
struct DexFieldId {
u2 classIdx; /* field所属的class类型,class_idx的值时type_ids的一个index,指向所属的类 */
u2 typeIdx; /* field的类型,值是type_ids的一个index */
u4 nameIdx; /* field的名称,它的值是string_ids的一个index */
};
仍然从header看起 重要的数据还是保存在头部
继续从010中尝试分析:
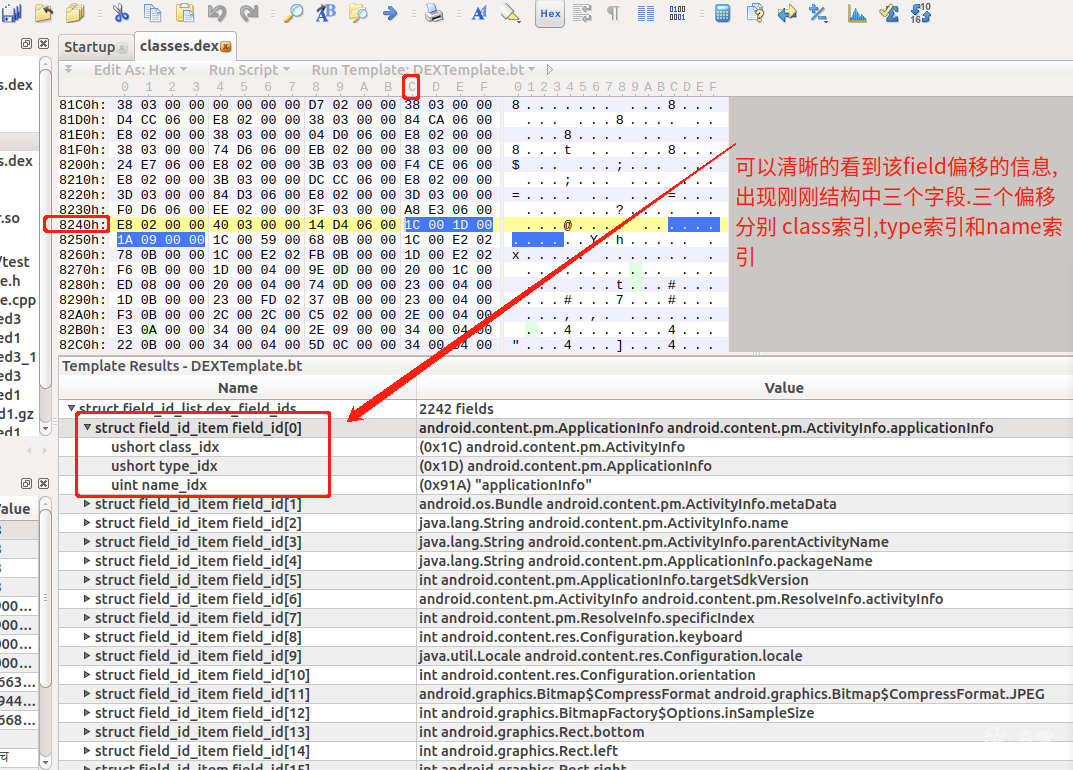
那么来到 824C
之前分析过type 这次 分析结构中的 type_idx
上图可见 type_idx的地址的值内容为 0x1D 也就是 29
可以看到 他们的值是一致的!
另外2个原理一直,可以自行分析
截图截多了!不好意思!
4.1、解析DexFieldId
又开始写代码
比较麻烦的是取值的过程需要通过其他属性来取值
void Read_DexFieldId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct field_id_list dex_field_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->fieldIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexFieldId));
printf("\t\t\t数组,存储类的相关的信息");
//转为DexFieldId结构体
DexFieldId *dexFieldId = (DexFieldId*)(fp + dex->pHeader->fieldIdsOff);
for (int i = 0; i < dex->pHeader->fieldIdsSize; ++i) {
printf("\n\tstruct field_id_item field_id[%d]",i);
/**
* 重点:
* 要想找到field_id的typeIdx对应位置的值 要先找到 typeIdsOff偏移地址+typeIdx等于string_ids的索引,再通过string_ids来寻找值
*
* [类型偏移首地址+typeIdx索引] = 字符串所在的索引位置
* 字符串偏移首地址[字符串所在的索引位置] = [类型偏移首地址+typeIdx索引]的具体值
*/
//拿到类型的偏移首地址
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
//拿到字符串的偏移首地址
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
//类型偏移地址+索引=字符串索引
//字符串偏移+字符串索引=typeIdx位置具体的值
const u1* typeIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexFieldId->typeIdx))];
//解码
readUnsignedLeb128(&typeIdx_stringdata);
printf("\n\t\ttypeIdx --> ");
while(*typeIdx_stringdata != '\0')
{
printf("%c",(*typeIdx_stringdata));
typeIdx_stringdata++;
}
//u2 classIdx; /* field所属的class类型,class_idx的值时type_ids的一个index,指向所属的类 */
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexFieldId->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
//u4 nameIdx; /* field的名称,它的值是string_ids的一个index */
const u1* nameIdx_stringdata = (u1*)fp+stringIdsOff[(dexFieldId->nameIdx)];
//解码
readUnsignedLeb128(&nameIdx_stringdata);
printf("\n\t\tnameIdx --> ");
while(*nameIdx_stringdata != '\0')
{
printf("%c",(*nameIdx_stringdata));
nameIdx_stringdata++;
}
dexFieldId++;
}
}
输出
010
5、DexMethodId
5.0、理解DexMethodId
DexMethodId* pMethodIds; //数组,存储成员函数信息包括函数名 参数和返回值类型<br>
查看具体结构
描述的比较清晰
struct DexMethodId {
u2 classIdx; /* method所属的class类型,class_idx的值是type_ids的一个index,必须指向一个class类型 */
u2 protoIdx; /* method的原型,指向proto_ids的一个index */
u4 nameIdx; /* method的名称,值为string_ids的一个index */
};
可以自己尝试手动分析了,这里就不过多的演示了..之前演示很多次了
5.1、解析DexMethodId
又开始写代码了
void Read_DexMethodId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct method_id_list dex_method_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->methodIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,存储成员函数信息包括函数名 参数和返回值类型");
//转为DexMethodId结构体
DexMethodId *dexMethodId = (DexMethodId*)(fp + dex->pHeader->methodIdsOff);
for (int i = 0; i < dex->pHeader->methodIdsSize; ++i) {
printf("\n\tstruct method_id_item method_id[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *protoIdsOff = (int*)(fp + dex->pHeader->protoIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexMethodId->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
//method的原型,指向proto_ids的一个index
DexProtoId* dexProtoId = (DexProtoId*) protoIdsOff+dexMethodId->protoIdx;
const u1* protoIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexProtoId->returnTypeIdx))];
readUnsignedLeb128(&protoIdx_stringdata);
printf("\n\t\tprotoIdx--> ");
while(*protoIdx_stringdata != '\0')
{
printf("%c",(*protoIdx_stringdata));
protoIdx_stringdata++;
}
const u1* nameIdx_stringdata = (u1*)fp+stringIdsOff[dexMethodId->nameIdx];
//解码
readUnsignedLeb128(&nameIdx_stringdata);
printf("\n\t\tnameIdx --> ");
while(*nameIdx_stringdata != '\0')
{
printf("%c",(*nameIdx_stringdata));
nameIdx_stringdata++;
}
dexMethodId++;
}
}
输出:
010
6、DexProtoId
6.0、理解DexProtoId
DexProtoId* pProtoIds; //数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表
具体结构
struct DexProtoId {
u4 shortyIdx; /* 值为一个string_ids的index号,用来说明该method原型 */
u4 returnTypeIdx; /* 值为一个type_ids的index,表示该method原型的返回值类型 */
u4 parametersOff; /* 指定method原型的参数列表type_list,若method没有参数,则值为0. 参数的格式是type_list */
};
6.0、解析DexProtoId
void Read_DexProtoId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct proto_id_list dex_proto_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->protoIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表");
//转为DexMethodId结构体
DexProtoId *dexProtoId = (DexProtoId*)(fp + dex->pHeader->protoIdsOff);
for (int i = 0; i < dex->pHeader->protoIdsSize; ++i) {
printf("\n\tstruct proto_id_item proto_id[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* shortyIdx_stringdata = (u1*)fp+stringIdsOff[dexProtoId->shortyIdx];
//解码
readUnsignedLeb128(&shortyIdx_stringdata);
printf("\n\t\tshortyIdx--> ");
while(*shortyIdx_stringdata != '\0')
{
printf("%c",(*shortyIdx_stringdata));
shortyIdx_stringdata++;
}
const u1* returnTypeIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexProtoId->returnTypeIdx))];
readUnsignedLeb128(&returnTypeIdx_stringdata);
printf("\n\t\tprotoIdx--> ");
while(*returnTypeIdx_stringdata != '\0')
{
printf("%c",(*returnTypeIdx_stringdata));
returnTypeIdx_stringdata++;
}
printf("\n\t\tparametersOff--> %d",dexProtoId->parametersOff);
dexProtoId++;
}
}
输出:
010:
7、DexClassDef
7.0、理解DexClassDef
DexClassDef* pClassDefs; //数组,存储类的信息
结构体
struct DexClassDef {
u4 classIdx; /* 描述具体的class类型,值是type_ids的一个index,值必须是一个class类型,不能是数组或者基本类型 */
u4 accessFlags; /* 描述class的访问类型,如public,final,static等 */
u4 superclassIdx; /* 描述父类的类型,值必须是一个class类型,不能是数组雷兴国或者基本类型 */
u4 interfacesOff; /* 值为偏移地址,被指向的数据结构为type_list,class若没有interfaces,值为0 */
u4 sourceFileIdx; /* 表示源代码文件的信息,值为string_ids的一个index。若此项信息丢失,此项赋值为NO_INDEX=0xFFFFFFFF */
u4 annotationsOff; /* 值为偏移地址,指向的内容是该class的注解,位置在data区,格式为annotations_directory_item,若没有此项,值为0 */
u4 classDataOff; /* 值为偏移地址,指向的内容是该class的使用到的数据,位置在data区,格式为class_data_item。无偶没有此项,则值为0 */
u4 staticValuesOff; /* 值为偏移地址,指向data区里的一个列表,格式为encoded_array_item。若没有此项,值为0. */
};
解析:
void Read_DexClassDef(char* fp)
{
//u4 classIdx; /* 描述具体的class类型,值是type_ids的一个index,值必须是一个class类型,不能是数组或者基本类型 */
//u4 accessFlags; /* 描述class的访问类型,如public,final,static等 */
//u4 superclassIdx; /* 描述父类的类型,值必须是一个class类型,不能是数组或者基本类型 */
//u4 interfacesOff; /* 值为偏移地址,被指向的数据结构为type_list,class若没有interfaces,值为0 */
//u4 sourceFileIdx; /* 表示源代码文件的信息,值为string_ids的一个index。若此项信息丢失,此项赋值为NO_INDEX=0xFFFFFFFF */
//u4 annotationsOff; /* 值为偏移地址,指向的内容是该class的注解,位置在data区,格式为annotations_directory_item,若没有此项,值为0 */
//u4 classDataOff; /* 值为偏移地址,指向的内容是该class的使用到的数据,位置在data区,格式为class_data_item。无偶没有此项,则值为0 */
//u4 staticValuesOff; /* 值为偏移地址,指向data区里的一个列表,格式为encoded_array_item。若没有此项,值为0. */
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct class_def_item_list dex_class_defs\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->classDefsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,存储类的信息");
//转为DexMethodId结构体
DexClassDef *dexClassDef = (DexClassDef*)(fp + dex->pHeader->classDefsOff);
for (int i = 0; i < dex->pHeader->classDefsSize; ++i) {
printf("\n\tstruct class_def_item class_def[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexClassDef->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx\t\t--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
printf("\n\t\taccessFlags\t\t-->\t%x",dexClassDef->accessFlags);
//通过类型去寻找
const u1* superclassIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexClassDef->superclassIdx))];
//解码
readUnsignedLeb128(&superclassIdx_stringdata);
printf("\n\t\tsuperclassIdx\t--> ");
while(*superclassIdx_stringdata != '\0')
{
printf("%c",(*superclassIdx_stringdata));
superclassIdx_stringdata++;
}
printf("\n\t\tinterfacesOff\t-->\t%d",dexClassDef->interfacesOff);
if (dexClassDef->sourceFileIdx == -1)
{
printf("\n\t\tsourceFileIdx\t-->\tNO_INDEX");
}
printf("\n\t\tannotationsOff\t-->\t%d",dexClassDef->annotationsOff);
printf("\n\t\tclassDataOff\t-->\t%d",dexClassDef->classDataOff);
printf("\n\t\tstaticValuesOff\t-->\t%d",dexClassDef->staticValuesOff);
dexClassDef++;
}
}输出:
010:
代码写的比较乱,在这次学习中收获挺多的..
各位大神看完了有什么错的那啥,,轻点,,
u1 signature[kSHA1DigestLen]; //签名信息,不包括 magic\checksum和自己
kSHA1DigestLen:
/*
* 160-bit SHA-1 digest.
*/
enum { kSHA1DigestLen = 20,
kSHA1DigestOutputLen = kSHA1DigestLen*2 +1 };
fileSize:文件长度
u4 fileSize; //整个文件的长度,单位为字节,包括所有的内容
553820个字节大小
表示 DexHeader 头结构的大小,占用4个字节。这里可以看到它一共占用了112个字节,112对应的16进制数为70h
u4 headerSize; //默认是0x70个字节
u4 endianTag; //大小端标签,标准.dex文件为小端,此项一般固定为0x12345678常量
0
当多个class文件被编译到一个dex文件是,他们会用到link_size和link_off,通常为0
u4 linkSize; //链接数据的大小
u4 linkOff; //链接数据的偏移值
mapOff字段了,它指定了 DexMapList 的文件偏移
u4 mapOff; //map item的偏移地址,该item属于data区里的内容,值要大于等于dataOff的大小
stringIdsSize代表全dex文件的字符串的个数
stringIdsOff 代表全dex文件的字符串的偏移
u4 stringIdsSize; //DEX中用到的所有字符串内容的大小*
u4 stringIdsOff; //DEX中用到的所有字符串内容的偏移量
有了这个知识 可以尝试分析第一个字符串
已经找到第一个字符串的偏移是6e72c
那么也就找到了 第一个字符串的值 虽然看不明显但确实如此
以上的2个问题会在解析中给出答案!
这指出了type类型的偏移和type的个数
u4 typeIdsSize; //DEX中类型数据结构的大小
u4 typeIdsOff; //DEX中类型数据结构的偏移值
略...
u4 protoIdsSize; //DEX中的元数据信息数据结构的大小
u4 protoIdsOff; //DEX中的元数据信息数据结构的偏移值
u4 fieldIdsSize; //DEX中字段信息数据结构的大小
u4 fieldIdsOff; //DEX中字段信息数据结构的偏移值
u4 methodIdsSize; //DEX中方法信息数据结构的大小
u4 methodIdsOff; //DEX中方法信息数据结构的偏移值
u4 classDefsSize; //DEX中的类信息数据结构的大小
u4 classDefsOff; //DEX中的类信息数据结构的偏移值
u4 dataSize; //DEX中数据区域的结构信息的大小
u4 dataOff; //DEX中数据区域的结构信息的偏移值
1.1、解析DexHeader
那么就开始动手写的代码来解析吧~~
用的Clion编译器
1.
首先 先写个一个读取文件的方法
char* Read_File(string file_Path) {
filebuf *pbuf;
ifstream filestr;
long size;
char *buffer;
// 要读入整个文件,必须采用二进制打开
filestr.open(file_Path, ios::binary);
// 获取filestr对应buffer对象的指针
pbuf = filestr.rdbuf();
// 调用buffer对象方法获取文件大小
size = pbuf->pubseekoff(0, ios::end, ios::in);
pbuf->pubseekpos(0, ios::in);
// 分配内存空间
buffer = new char[size];
// 获取文件内容
pbuf->sgetn(buffer, size);
filestr.close();
// 输出到标准输出
//cout.write (buffer,size);
// delete []buffer;
return buffer;
}
2.
main:
//得到文件内存地址指针
char* fp = Read_File("/home/zlq/baidunetdiskdownload/android/classes.dex");
//强转为DexFile指针
DexFile *dex = (DexFile*)&fp;
//解析struct header_item dex_header
Read_DexHeader(dex->pHeader);
3.
写的比较拙劣,,,,
/**
* 实现方法
* @param dexHeader
*/
void Read_DexHeader(DexHeader* dexHeader)
{
//struct header_item dex_header
printf("struct header_item dex_header\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t0x0");
printf("\t\t\t\t0x%x", (unsigned int)sizeof(DexHeader));
printf("\t\tDEX 文件头,记录了一些当前文件的信息以及其他数据结构在文件中的偏移量");
printf("\n\tmagic\t\t\t\t\t\t\t\t");
char* magic = (char*)dexHeader->magic;
while(*magic != '\0')
{
if(*magic != '\n')
{
printf("%c ",(*magic));
}
magic++;
}
printf("\t\t\t\t\t\t\t\t\t\t0x0\t\t\t\t0x%x\t\t\t取值必须是字符串 \"dex\\n035\\0\" 或者字节byte数组 {0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00}",
(unsigned int)sizeof(dexHeader->magic));
printf("\n\tchecksum\t\t\t\t\t\t\t0x%X\t\t\t\t\t\t\t\t\t\t\t0x%x\t\t\t\t0x%x\t\t\t文件内容的校验和,不包括magic和自己,主要用于检查文件是否损坏"
,dexHeader->checksum
,(unsigned int)sizeof(dexHeader->magic)
,(unsigned int)sizeof(dexHeader->checksum));
.... 略
输出
通过对比分析是一样的
这个比较简单,用结构指针接受一下就行了 只是输出有点麻烦
2、 DexStringId
2.0、理解DexStringId
DEX中所有的字符串存储在这里
DexStringId* pStringIds; //数组,元素类型为string_id_item,存储字符串相关的信息
进去看看此结构!
它只有一个字段,那么它是如何解析dex字符串呢?
/*
* Direct-mapped "string_id_item".
*/
struct DexStringId {
//用于指明 string_data_item 位置文件的位置
u4 stringDataOff; /* file offset to string_data_item */
};首先要知道的是它是一个数组类型,数组的大小取决于
DexHeader->stringIdsSize
那么就很好理解了,上面提示 一共 有3619个 字符串
解析主要靠DexHeader中的stringIdsSize和stringIdsOff来解析
2.0、解析DexStringId
又开始写代码了
void Read_DexStringId(char* fp) {
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct string_id_list dex_string_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->stringIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexStringId));
printf("\t\t\t数组,元素类型为string_id_item,存储字符串相关的信息");
//拿到字符串的偏移
int *p2 = (int*)(fp + dex->pHeader->stringIdsOff);
////stringIdsSize --> DEX中用到的所有字符串内容的大小
for (int i = 0; i < dex->pHeader->stringIdsSize; ++i) {
printf("\n\tstruct string_id_item string_id[%d]:",i);
// 文件首地址+字符串偏移就是字符串存放的位置的第一个数组
const u1* stringdata = (u1*)fp+*p2;
//解码
/*
* dex文件里采用了变长方式表示字符串长度。一个字符串的长度可能是一个字节(小于256)或者4个字节(1G大小以上)。字符串的长度大多数都是小于 256个字节,因此需要使用一种编码,既可以表示一个字节的长度,也可以表示4个字节的长度,并且1个字节的长度占绝大多数。能满足这种表示的编码方式有很多,但dex文件里采用的是uleb128方式。leb128编码是一种变长编码,每个字节采用7位来表达原来的数据,最高位用来表示是否有后继字节。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高位为 0 。每个 Byte 的其余 Bit 用来表示数据
*/
readUnsignedLeb128(&stringdata);
//转码后该字符串为 内存数据为 \0 时 则结束
while(*stringdata != '\0')
{
//换行
if((*stringdata) != '\a' && (*stringdata) != '\b' &&(*stringdata) != '\t' && (*stringdata) != '\n' && (*stringdata) != '\v' && (*stringdata) != '\r' && (*stringdata) != '\f' )
{
printf("%c",(*stringdata));
}
//printf("%c",(*stringdata));
stringdata++;
}
p2++;
}
}
其中一部分的输出:
010:
总结:
* dex->pHeader->stringIdsOff 存储了整个dex的字符串的偏移的首地址 是一个数组类型
* dex->pHeader->stringIdsSize 存储字符串的个数
* 字符串偏移指向的地址的内容通过 readUnsignedLeb128 解码 字符串的长度通过判断'\0' 即可
编码:
LEB128即"Little-Endian Base 128",基于128的小印第安序编码格式,是对任意有符号或者无符号整型数的可变长度的编码。
也即,用LEB128编码的正数,会根据数字的大小改变所占字节数。在android的.dex文件中,他只用来编码32bits的整型数。
格式:
图只是指示性的用两个字节表示。编码的每个字节有效部分只有低7bits,每个字节的最高bit用来指示是否是最后一个字节。
非最高字节的bit7为0
最高字节的bit7为1
将leb128编码的数字转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
比如:
LEB128编码的0x02b0 ---> 转换后的数字0x0130
转换过程:
0x02b0 ---> 0000 0010 1011 0000 -->去除最高位--> 000 0010 011 0000 -->按4bits重排 --> 00 0001 0011 0000 --> 0x130
引用 https://blog.csdn.net/Roland_Sun/article/details/46708061
3、DexTypeId
3.0、理解DexTypeId
* type_ids 区索引了 .dex 文件里的所有数据类型 ,包括 class 类型 ,数组类型(array types)和基本类型(primitive types) 。 本区域里的元素格式为type_ids_item
* type_ids_item 里面 descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串 。
DexTypeId* pTypeIds; //数组,存储类型相关的信息
看结构
他也是一个字段,且看如何分析它
注意是一个数组的类型
/*
* Direct-mapped "type_id_item".
*/
struct DexTypeId {
u4 descriptorIdx; /* 指向string_ids的索引 */
};
同时 还有2个很重要的字段在DexHeader中typeIdsSize和typeIdsOff 同样代表类型的偏移和大小.
先来分析第一个type:
得知第一个type所在位置是 00 00 38 FC
010
得到的值是 0x19F
根据描述 /* 指向string_ids的索引 */ 知道这个值是字符串偏移的索引
0x19F = 415
恰好是第一个类型的值 : B byte
如此就分析出第一个类型的位置和来源了
3.0、解析DexTypeId
又开始写代码:
void Read_DexTypeId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct struct type_id_list dex_type_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->typeIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexTypeId));
printf("\t\t\t数组,存储类型相关的信息\n");
//拿到类型的偏移
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
for (int i = 0; i < dex->pHeader->typeIdsSize; ++i) {
printf("\n\tstruct type_id_list dex_type_ids[%d]:",i);
//先拿到字符串的偏移
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
//再根据类型的偏移去寻找字符串
const u1* stringdata = (u1*)fp+stringIdsOff[(*typeIdsOff)];
//解码
readUnsignedLeb128(&stringdata);
while(*stringdata != '\0')
{
printf("%c",(*stringdata));
stringdata++;
}
//自加 获取下一个指针 int型指针自加 base += 1
typeIdsOff++;
}
}
输出:
010:
总结:
descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串
字符串指针[descriptor_idx地址内的值] = descriptor_idx值
4、DexFieldId
4.0、理解DexFieldId
大意:
DexFieldId* pFieldIds; //数组,存储成员变量信息,包括变量名和类型等
具体结构:
struct DexFieldId {
u2 classIdx; /* field所属的class类型,class_idx的值时type_ids的一个index,指向所属的类 */
u2 typeIdx; /* field的类型,值是type_ids的一个index */
u4 nameIdx; /* field的名称,它的值是string_ids的一个index */
};
仍然从header看起 重要的数据还是保存在头部
继续从010中尝试分析:
那么来到 824C
之前分析过type 这次 分析结构中的 type_idx
上图可见 type_idx的地址的值内容为 0x1D 也就是 29
可以看到 他们的值是一致的!
另外2个原理一直,可以自行分析
截图截多了!不好意思!
4.1、解析DexFieldId
又开始写代码
比较麻烦的是取值的过程需要通过其他属性来取值
void Read_DexFieldId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct field_id_list dex_field_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->fieldIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexFieldId));
printf("\t\t\t数组,存储类的相关的信息");
//转为DexFieldId结构体
DexFieldId *dexFieldId = (DexFieldId*)(fp + dex->pHeader->fieldIdsOff);
for (int i = 0; i < dex->pHeader->fieldIdsSize; ++i) {
printf("\n\tstruct field_id_item field_id[%d]",i);
/**
* 重点:
* 要想找到field_id的typeIdx对应位置的值 要先找到 typeIdsOff偏移地址+typeIdx等于string_ids的索引,再通过string_ids来寻找值
*
* [类型偏移首地址+typeIdx索引] = 字符串所在的索引位置
* 字符串偏移首地址[字符串所在的索引位置] = [类型偏移首地址+typeIdx索引]的具体值
*/
//拿到类型的偏移首地址
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
//拿到字符串的偏移首地址
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
//类型偏移地址+索引=字符串索引
//字符串偏移+字符串索引=typeIdx位置具体的值
const u1* typeIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexFieldId->typeIdx))];
//解码
readUnsignedLeb128(&typeIdx_stringdata);
printf("\n\t\ttypeIdx --> ");
while(*typeIdx_stringdata != '\0')
{
printf("%c",(*typeIdx_stringdata));
typeIdx_stringdata++;
}
//u2 classIdx; /* field所属的class类型,class_idx的值时type_ids的一个index,指向所属的类 */
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexFieldId->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
//u4 nameIdx; /* field的名称,它的值是string_ids的一个index */
const u1* nameIdx_stringdata = (u1*)fp+stringIdsOff[(dexFieldId->nameIdx)];
//解码
readUnsignedLeb128(&nameIdx_stringdata);
printf("\n\t\tnameIdx --> ");
while(*nameIdx_stringdata != '\0')
{
printf("%c",(*nameIdx_stringdata));
nameIdx_stringdata++;
}
dexFieldId++;
}
}
输出
010
5、DexMethodId
5.0、理解DexMethodId
DexMethodId* pMethodIds; //数组,存储成员函数信息包括函数名 参数和返回值类型<br>
查看具体结构
描述的比较清晰
struct DexMethodId {
u2 classIdx; /* method所属的class类型,class_idx的值是type_ids的一个index,必须指向一个class类型 */
u2 protoIdx; /* method的原型,指向proto_ids的一个index */
u4 nameIdx; /* method的名称,值为string_ids的一个index */
};
可以自己尝试手动分析了,这里就不过多的演示了..之前演示很多次了
5.1、解析DexMethodId
又开始写代码了
void Read_DexMethodId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct method_id_list dex_method_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->methodIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,存储成员函数信息包括函数名 参数和返回值类型");
//转为DexMethodId结构体
DexMethodId *dexMethodId = (DexMethodId*)(fp + dex->pHeader->methodIdsOff);
for (int i = 0; i < dex->pHeader->methodIdsSize; ++i) {
printf("\n\tstruct method_id_item method_id[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *protoIdsOff = (int*)(fp + dex->pHeader->protoIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexMethodId->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
//method的原型,指向proto_ids的一个index
DexProtoId* dexProtoId = (DexProtoId*) protoIdsOff+dexMethodId->protoIdx;
const u1* protoIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexProtoId->returnTypeIdx))];
readUnsignedLeb128(&protoIdx_stringdata);
printf("\n\t\tprotoIdx--> ");
while(*protoIdx_stringdata != '\0')
{
printf("%c",(*protoIdx_stringdata));
protoIdx_stringdata++;
}
const u1* nameIdx_stringdata = (u1*)fp+stringIdsOff[dexMethodId->nameIdx];
//解码
readUnsignedLeb128(&nameIdx_stringdata);
printf("\n\t\tnameIdx --> ");
while(*nameIdx_stringdata != '\0')
{
printf("%c",(*nameIdx_stringdata));
nameIdx_stringdata++;
}
dexMethodId++;
}
}
输出:
010
6、DexProtoId
6.0、理解DexProtoId
DexProtoId* pProtoIds; //数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表
具体结构
struct DexProtoId {
u4 shortyIdx; /* 值为一个string_ids的index号,用来说明该method原型 */
u4 returnTypeIdx; /* 值为一个type_ids的index,表示该method原型的返回值类型 */
u4 parametersOff; /* 指定method原型的参数列表type_list,若method没有参数,则值为0. 参数的格式是type_list */
};
6.0、解析DexProtoId
void Read_DexProtoId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct proto_id_list dex_proto_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->protoIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表");
//转为DexMethodId结构体
DexProtoId *dexProtoId = (DexProtoId*)(fp + dex->pHeader->protoIdsOff);
for (int i = 0; i < dex->pHeader->protoIdsSize; ++i) {
printf("\n\tstruct proto_id_item proto_id[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* shortyIdx_stringdata = (u1*)fp+stringIdsOff[dexProtoId->shortyIdx];
//解码
readUnsignedLeb128(&shortyIdx_stringdata);
printf("\n\t\tshortyIdx--> ");
while(*shortyIdx_stringdata != '\0')
{
printf("%c",(*shortyIdx_stringdata));
shortyIdx_stringdata++;
}
const u1* returnTypeIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexProtoId->returnTypeIdx))];
readUnsignedLeb128(&returnTypeIdx_stringdata);
printf("\n\t\tprotoIdx--> ");
while(*returnTypeIdx_stringdata != '\0')
{
printf("%c",(*returnTypeIdx_stringdata));
returnTypeIdx_stringdata++;
}
printf("\n\t\tparametersOff--> %d",dexProtoId->parametersOff);
dexProtoId++;
}
}
输出:
010:
7、DexClassDef
7.0、理解DexClassDef
DexClassDef* pClassDefs; //数组,存储类的信息
结构体
struct DexClassDef {
u4 classIdx; /* 描述具体的class类型,值是type_ids的一个index,值必须是一个class类型,不能是数组或者基本类型 */
u4 accessFlags; /* 描述class的访问类型,如public,final,static等 */
u4 superclassIdx; /* 描述父类的类型,值必须是一个class类型,不能是数组雷兴国或者基本类型 */
u4 interfacesOff; /* 值为偏移地址,被指向的数据结构为type_list,class若没有interfaces,值为0 */
u4 sourceFileIdx; /* 表示源代码文件的信息,值为string_ids的一个index。若此项信息丢失,此项赋值为NO_INDEX=0xFFFFFFFF */
u4 annotationsOff; /* 值为偏移地址,指向的内容是该class的注解,位置在data区,格式为annotations_directory_item,若没有此项,值为0 */
u4 classDataOff; /* 值为偏移地址,指向的内容是该class的使用到的数据,位置在data区,格式为class_data_item。无偶没有此项,则值为0 */
u4 staticValuesOff; /* 值为偏移地址,指向data区里的一个列表,格式为encoded_array_item。若没有此项,值为0. */
};
解析:
void Read_DexClassDef(char* fp)
{
//u4 classIdx; /* 描述具体的class类型,值是type_ids的一个index,值必须是一个class类型,不能是数组或者基本类型 */
//u4 accessFlags; /* 描述class的访问类型,如public,final,static等 */
//u4 superclassIdx; /* 描述父类的类型,值必须是一个class类型,不能是数组或者基本类型 */
//u4 interfacesOff; /* 值为偏移地址,被指向的数据结构为type_list,class若没有interfaces,值为0 */
//u4 sourceFileIdx; /* 表示源代码文件的信息,值为string_ids的一个index。若此项信息丢失,此项赋值为NO_INDEX=0xFFFFFFFF */
//u4 annotationsOff; /* 值为偏移地址,指向的内容是该class的注解,位置在data区,格式为annotations_directory_item,若没有此项,值为0 */
//u4 classDataOff; /* 值为偏移地址,指向的内容是该class的使用到的数据,位置在data区,格式为class_data_item。无偶没有此项,则值为0 */
//u4 staticValuesOff; /* 值为偏移地址,指向data区里的一个列表,格式为encoded_array_item。若没有此项,值为0. */
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct class_def_item_list dex_class_defs\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->classDefsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,存储类的信息");
//转为DexMethodId结构体
DexClassDef *dexClassDef = (DexClassDef*)(fp + dex->pHeader->classDefsOff);
for (int i = 0; i < dex->pHeader->classDefsSize; ++i) {
printf("\n\tstruct class_def_item class_def[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexClassDef->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx\t\t--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
printf("\n\t\taccessFlags\t\t-->\t%x",dexClassDef->accessFlags);
//通过类型去寻找
const u1* superclassIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexClassDef->superclassIdx))];
//解码
readUnsignedLeb128(&superclassIdx_stringdata);
printf("\n\t\tsuperclassIdx\t--> ");
while(*superclassIdx_stringdata != '\0')
{
printf("%c",(*superclassIdx_stringdata));
superclassIdx_stringdata++;
}
printf("\n\t\tinterfacesOff\t-->\t%d",dexClassDef->interfacesOff);
if (dexClassDef->sourceFileIdx == -1)
{
printf("\n\t\tsourceFileIdx\t-->\tNO_INDEX");
}
printf("\n\t\tannotationsOff\t-->\t%d",dexClassDef->annotationsOff);
printf("\n\t\tclassDataOff\t-->\t%d",dexClassDef->classDataOff);
printf("\n\t\tstaticValuesOff\t-->\t%d",dexClassDef->staticValuesOff);
dexClassDef++;
}
}输出:
010:
代码写的比较乱,在这次学习中收获挺多的..
各位大神看完了有什么错的那啥,,轻点,,
/*
* 160-bit SHA-1 digest.
*/
enum { kSHA1DigestLen = 20,
kSHA1DigestOutputLen = kSHA1DigestLen*2 +1 };
fileSize:文件长度
u4 fileSize; //整个文件的长度,单位为字节,包括所有的内容
553820个字节大小
表示 DexHeader 头结构的大小,占用4个字节。这里可以看到它一共占用了112个字节,112对应的16进制数为70h
u4 headerSize; //默认是0x70个字节
u4 endianTag; //大小端标签,标准.dex文件为小端,此项一般固定为0x12345678常量
0
当多个class文件被编译到一个dex文件是,他们会用到link_size和link_off,通常为0
u4 linkSize; //链接数据的大小
u4 linkOff; //链接数据的偏移值
mapOff字段了,它指定了 DexMapList 的文件偏移
u4 mapOff; //map item的偏移地址,该item属于data区里的内容,值要大于等于dataOff的大小
stringIdsSize代表全dex文件的字符串的个数
stringIdsOff 代表全dex文件的字符串的偏移
u4 stringIdsSize; //DEX中用到的所有字符串内容的大小*
u4 stringIdsOff; //DEX中用到的所有字符串内容的偏移量
有了这个知识 可以尝试分析第一个字符串
已经找到第一个字符串的偏移是6e72c
那么也就找到了 第一个字符串的值 虽然看不明显但确实如此
以上的2个问题会在解析中给出答案!
这指出了type类型的偏移和type的个数
u4 typeIdsSize; //DEX中类型数据结构的大小
u4 typeIdsOff; //DEX中类型数据结构的偏移值
略...
u4 protoIdsSize; //DEX中的元数据信息数据结构的大小
u4 protoIdsOff; //DEX中的元数据信息数据结构的偏移值
u4 fieldIdsSize; //DEX中字段信息数据结构的大小
u4 fieldIdsOff; //DEX中字段信息数据结构的偏移值
u4 methodIdsSize; //DEX中方法信息数据结构的大小
u4 methodIdsOff; //DEX中方法信息数据结构的偏移值
u4 classDefsSize; //DEX中的类信息数据结构的大小
u4 classDefsOff; //DEX中的类信息数据结构的偏移值
u4 dataSize; //DEX中数据区域的结构信息的大小
u4 dataOff; //DEX中数据区域的结构信息的偏移值
1.1、解析DexHeader
那么就开始动手写的代码来解析吧~~
用的Clion编译器
1.
首先 先写个一个读取文件的方法
char* Read_File(string file_Path) {
filebuf *pbuf;
ifstream filestr;
long size;
char *buffer;
// 要读入整个文件,必须采用二进制打开
filestr.open(file_Path, ios::binary);
// 获取filestr对应buffer对象的指针
pbuf = filestr.rdbuf();
// 调用buffer对象方法获取文件大小
size = pbuf->pubseekoff(0, ios::end, ios::in);
pbuf->pubseekpos(0, ios::in);
// 分配内存空间
buffer = new char[size];
// 获取文件内容
pbuf->sgetn(buffer, size);
filestr.close();
// 输出到标准输出
//cout.write (buffer,size);
// delete []buffer;
return buffer;
}
2.
main:
//得到文件内存地址指针
char* fp = Read_File("/home/zlq/baidunetdiskdownload/android/classes.dex");
//强转为DexFile指针
DexFile *dex = (DexFile*)&fp;
//解析struct header_item dex_header
Read_DexHeader(dex->pHeader);
3.
写的比较拙劣,,,,
/**
* 实现方法
* @param dexHeader
*/
void Read_DexHeader(DexHeader* dexHeader)
{
//struct header_item dex_header
printf("struct header_item dex_header\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t0x0");
printf("\t\t\t\t0x%x", (unsigned int)sizeof(DexHeader));
printf("\t\tDEX 文件头,记录了一些当前文件的信息以及其他数据结构在文件中的偏移量");
printf("\n\tmagic\t\t\t\t\t\t\t\t");
char* magic = (char*)dexHeader->magic;
while(*magic != '\0')
{
if(*magic != '\n')
{
printf("%c ",(*magic));
}
magic++;
}
printf("\t\t\t\t\t\t\t\t\t\t0x0\t\t\t\t0x%x\t\t\t取值必须是字符串 \"dex\\n035\\0\" 或者字节byte数组 {0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00}",
(unsigned int)sizeof(dexHeader->magic));
printf("\n\tchecksum\t\t\t\t\t\t\t0x%X\t\t\t\t\t\t\t\t\t\t\t0x%x\t\t\t\t0x%x\t\t\t文件内容的校验和,不包括magic和自己,主要用于检查文件是否损坏"
,dexHeader->checksum
,(unsigned int)sizeof(dexHeader->magic)
,(unsigned int)sizeof(dexHeader->checksum));
.... 略
输出
通过对比分析是一样的
这个比较简单,用结构指针接受一下就行了 只是输出有点麻烦
2、 DexStringId
2.0、理解DexStringId
DEX中所有的字符串存储在这里
DexStringId* pStringIds; //数组,元素类型为string_id_item,存储字符串相关的信息
进去看看此结构!
它只有一个字段,那么它是如何解析dex字符串呢?
/*
* Direct-mapped "string_id_item".
*/
struct DexStringId {
//用于指明 string_data_item 位置文件的位置
u4 stringDataOff; /* file offset to string_data_item */
};首先要知道的是它是一个数组类型,数组的大小取决于
DexHeader->stringIdsSize
那么就很好理解了,上面提示 一共 有3619个 字符串
解析主要靠DexHeader中的stringIdsSize和stringIdsOff来解析
2.0、解析DexStringId
又开始写代码了
void Read_DexStringId(char* fp) {
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct string_id_list dex_string_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->stringIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexStringId));
printf("\t\t\t数组,元素类型为string_id_item,存储字符串相关的信息");
//拿到字符串的偏移
int *p2 = (int*)(fp + dex->pHeader->stringIdsOff);
////stringIdsSize --> DEX中用到的所有字符串内容的大小
for (int i = 0; i < dex->pHeader->stringIdsSize; ++i) {
printf("\n\tstruct string_id_item string_id[%d]:",i);
// 文件首地址+字符串偏移就是字符串存放的位置的第一个数组
const u1* stringdata = (u1*)fp+*p2;
//解码
/*
* dex文件里采用了变长方式表示字符串长度。一个字符串的长度可能是一个字节(小于256)或者4个字节(1G大小以上)。字符串的长度大多数都是小于 256个字节,因此需要使用一种编码,既可以表示一个字节的长度,也可以表示4个字节的长度,并且1个字节的长度占绝大多数。能满足这种表示的编码方式有很多,但dex文件里采用的是uleb128方式。leb128编码是一种变长编码,每个字节采用7位来表达原来的数据,最高位用来表示是否有后继字节。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高位为 0 。每个 Byte 的其余 Bit 用来表示数据
*/
readUnsignedLeb128(&stringdata);
//转码后该字符串为 内存数据为 \0 时 则结束
while(*stringdata != '\0')
{
//换行
if((*stringdata) != '\a' && (*stringdata) != '\b' &&(*stringdata) != '\t' && (*stringdata) != '\n' && (*stringdata) != '\v' && (*stringdata) != '\r' && (*stringdata) != '\f' )
{
printf("%c",(*stringdata));
}
//printf("%c",(*stringdata));
stringdata++;
}
p2++;
}
}
其中一部分的输出:
010:
总结:
* dex->pHeader->stringIdsOff 存储了整个dex的字符串的偏移的首地址 是一个数组类型
* dex->pHeader->stringIdsSize 存储字符串的个数
* 字符串偏移指向的地址的内容通过 readUnsignedLeb128 解码 字符串的长度通过判断'\0' 即可
编码:
LEB128即"Little-Endian Base 128",基于128的小印第安序编码格式,是对任意有符号或者无符号整型数的可变长度的编码。
也即,用LEB128编码的正数,会根据数字的大小改变所占字节数。在android的.dex文件中,他只用来编码32bits的整型数。
格式:
图只是指示性的用两个字节表示。编码的每个字节有效部分只有低7bits,每个字节的最高bit用来指示是否是最后一个字节。
非最高字节的bit7为0
最高字节的bit7为1
将leb128编码的数字转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
比如:
LEB128编码的0x02b0 ---> 转换后的数字0x0130
转换过程:
0x02b0 ---> 0000 0010 1011 0000 -->去除最高位--> 000 0010 011 0000 -->按4bits重排 --> 00 0001 0011 0000 --> 0x130
引用 https://blog.csdn.net/Roland_Sun/article/details/46708061
3、DexTypeId
3.0、理解DexTypeId
* type_ids 区索引了 .dex 文件里的所有数据类型 ,包括 class 类型 ,数组类型(array types)和基本类型(primitive types) 。 本区域里的元素格式为type_ids_item
* type_ids_item 里面 descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串 。
DexTypeId* pTypeIds; //数组,存储类型相关的信息
看结构
他也是一个字段,且看如何分析它
注意是一个数组的类型
/*
* Direct-mapped "type_id_item".
*/
struct DexTypeId {
u4 descriptorIdx; /* 指向string_ids的索引 */
};
同时 还有2个很重要的字段在DexHeader中typeIdsSize和typeIdsOff 同样代表类型的偏移和大小.
先来分析第一个type:
得知第一个type所在位置是 00 00 38 FC
010
得到的值是 0x19F
根据描述 /* 指向string_ids的索引 */ 知道这个值是字符串偏移的索引
0x19F = 415
恰好是第一个类型的值 : B byte
如此就分析出第一个类型的位置和来源了
3.0、解析DexTypeId
又开始写代码:
void Read_DexTypeId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct struct type_id_list dex_type_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->typeIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexTypeId));
printf("\t\t\t数组,存储类型相关的信息\n");
//拿到类型的偏移
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
for (int i = 0; i < dex->pHeader->typeIdsSize; ++i) {
printf("\n\tstruct type_id_list dex_type_ids[%d]:",i);
//先拿到字符串的偏移
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
//再根据类型的偏移去寻找字符串
const u1* stringdata = (u1*)fp+stringIdsOff[(*typeIdsOff)];
//解码
readUnsignedLeb128(&stringdata);
while(*stringdata != '\0')
{
printf("%c",(*stringdata));
stringdata++;
}
//自加 获取下一个指针 int型指针自加 base += 1
typeIdsOff++;
}
}
输出:
010:
总结:
descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串
字符串指针[descriptor_idx地址内的值] = descriptor_idx值
4、DexFieldId
4.0、理解DexFieldId
大意:
DexFieldId* pFieldIds; //数组,存储成员变量信息,包括变量名和类型等
具体结构:
struct DexFieldId {
u2 classIdx; /* field所属的class类型,class_idx的值时type_ids的一个index,指向所属的类 */
u2 typeIdx; /* field的类型,值是type_ids的一个index */
u4 nameIdx; /* field的名称,它的值是string_ids的一个index */
};
仍然从header看起 重要的数据还是保存在头部
继续从010中尝试分析:
那么来到 824C
之前分析过type 这次 分析结构中的 type_idx
上图可见 type_idx的地址的值内容为 0x1D 也就是 29
可以看到 他们的值是一致的!
另外2个原理一直,可以自行分析
截图截多了!不好意思!
4.1、解析DexFieldId
又开始写代码
比较麻烦的是取值的过程需要通过其他属性来取值
void Read_DexFieldId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct field_id_list dex_field_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->fieldIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexFieldId));
printf("\t\t\t数组,存储类的相关的信息");
//转为DexFieldId结构体
DexFieldId *dexFieldId = (DexFieldId*)(fp + dex->pHeader->fieldIdsOff);
for (int i = 0; i < dex->pHeader->fieldIdsSize; ++i) {
printf("\n\tstruct field_id_item field_id[%d]",i);
/**
* 重点:
* 要想找到field_id的typeIdx对应位置的值 要先找到 typeIdsOff偏移地址+typeIdx等于string_ids的索引,再通过string_ids来寻找值
*
* [类型偏移首地址+typeIdx索引] = 字符串所在的索引位置
* 字符串偏移首地址[字符串所在的索引位置] = [类型偏移首地址+typeIdx索引]的具体值
*/
//拿到类型的偏移首地址
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
//拿到字符串的偏移首地址
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
//类型偏移地址+索引=字符串索引
//字符串偏移+字符串索引=typeIdx位置具体的值
const u1* typeIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexFieldId->typeIdx))];
//解码
readUnsignedLeb128(&typeIdx_stringdata);
printf("\n\t\ttypeIdx --> ");
while(*typeIdx_stringdata != '\0')
{
printf("%c",(*typeIdx_stringdata));
typeIdx_stringdata++;
}
//u2 classIdx; /* field所属的class类型,class_idx的值时type_ids的一个index,指向所属的类 */
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexFieldId->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
//u4 nameIdx; /* field的名称,它的值是string_ids的一个index */
const u1* nameIdx_stringdata = (u1*)fp+stringIdsOff[(dexFieldId->nameIdx)];
//解码
readUnsignedLeb128(&nameIdx_stringdata);
printf("\n\t\tnameIdx --> ");
while(*nameIdx_stringdata != '\0')
{
printf("%c",(*nameIdx_stringdata));
nameIdx_stringdata++;
}
dexFieldId++;
}
}
输出
010
5、DexMethodId
5.0、理解DexMethodId
DexMethodId* pMethodIds; //数组,存储成员函数信息包括函数名 参数和返回值类型<br>
查看具体结构
描述的比较清晰
struct DexMethodId {
u2 classIdx; /* method所属的class类型,class_idx的值是type_ids的一个index,必须指向一个class类型 */
u2 protoIdx; /* method的原型,指向proto_ids的一个index */
u4 nameIdx; /* method的名称,值为string_ids的一个index */
};
可以自己尝试手动分析了,这里就不过多的演示了..之前演示很多次了
5.1、解析DexMethodId
又开始写代码了
void Read_DexMethodId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct method_id_list dex_method_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->methodIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,存储成员函数信息包括函数名 参数和返回值类型");
//转为DexMethodId结构体
DexMethodId *dexMethodId = (DexMethodId*)(fp + dex->pHeader->methodIdsOff);
for (int i = 0; i < dex->pHeader->methodIdsSize; ++i) {
printf("\n\tstruct method_id_item method_id[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *protoIdsOff = (int*)(fp + dex->pHeader->protoIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexMethodId->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
//method的原型,指向proto_ids的一个index
DexProtoId* dexProtoId = (DexProtoId*) protoIdsOff+dexMethodId->protoIdx;
const u1* protoIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexProtoId->returnTypeIdx))];
readUnsignedLeb128(&protoIdx_stringdata);
printf("\n\t\tprotoIdx--> ");
while(*protoIdx_stringdata != '\0')
{
printf("%c",(*protoIdx_stringdata));
protoIdx_stringdata++;
}
const u1* nameIdx_stringdata = (u1*)fp+stringIdsOff[dexMethodId->nameIdx];
//解码
readUnsignedLeb128(&nameIdx_stringdata);
printf("\n\t\tnameIdx --> ");
while(*nameIdx_stringdata != '\0')
{
printf("%c",(*nameIdx_stringdata));
nameIdx_stringdata++;
}
dexMethodId++;
}
}
输出:
010
6、DexProtoId
6.0、理解DexProtoId
DexProtoId* pProtoIds; //数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表
具体结构
struct DexProtoId {
u4 shortyIdx; /* 值为一个string_ids的index号,用来说明该method原型 */
u4 returnTypeIdx; /* 值为一个type_ids的index,表示该method原型的返回值类型 */
u4 parametersOff; /* 指定method原型的参数列表type_list,若method没有参数,则值为0. 参数的格式是type_list */
};
6.0、解析DexProtoId
void Read_DexProtoId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct proto_id_list dex_proto_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->protoIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表");
//转为DexMethodId结构体
DexProtoId *dexProtoId = (DexProtoId*)(fp + dex->pHeader->protoIdsOff);
for (int i = 0; i < dex->pHeader->protoIdsSize; ++i) {
printf("\n\tstruct proto_id_item proto_id[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* shortyIdx_stringdata = (u1*)fp+stringIdsOff[dexProtoId->shortyIdx];
//解码
readUnsignedLeb128(&shortyIdx_stringdata);
printf("\n\t\tshortyIdx--> ");
while(*shortyIdx_stringdata != '\0')
{
printf("%c",(*shortyIdx_stringdata));
shortyIdx_stringdata++;
}
const u1* returnTypeIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexProtoId->returnTypeIdx))];
readUnsignedLeb128(&returnTypeIdx_stringdata);
printf("\n\t\tprotoIdx--> ");
while(*returnTypeIdx_stringdata != '\0')
{
printf("%c",(*returnTypeIdx_stringdata));
returnTypeIdx_stringdata++;
}
printf("\n\t\tparametersOff--> %d",dexProtoId->parametersOff);
dexProtoId++;
}
}
输出:
010:
7、DexClassDef
7.0、理解DexClassDef
DexClassDef* pClassDefs; //数组,存储类的信息
结构体
struct DexClassDef {
u4 classIdx; /* 描述具体的class类型,值是type_ids的一个index,值必须是一个class类型,不能是数组或者基本类型 */
u4 accessFlags; /* 描述class的访问类型,如public,final,static等 */
u4 superclassIdx; /* 描述父类的类型,值必须是一个class类型,不能是数组雷兴国或者基本类型 */
u4 interfacesOff; /* 值为偏移地址,被指向的数据结构为type_list,class若没有interfaces,值为0 */
u4 sourceFileIdx; /* 表示源代码文件的信息,值为string_ids的一个index。若此项信息丢失,此项赋值为NO_INDEX=0xFFFFFFFF */
u4 annotationsOff; /* 值为偏移地址,指向的内容是该class的注解,位置在data区,格式为annotations_directory_item,若没有此项,值为0 */
u4 classDataOff; /* 值为偏移地址,指向的内容是该class的使用到的数据,位置在data区,格式为class_data_item。无偶没有此项,则值为0 */
u4 staticValuesOff; /* 值为偏移地址,指向data区里的一个列表,格式为encoded_array_item。若没有此项,值为0. */
};
解析:
void Read_DexClassDef(char* fp)
{
//u4 classIdx; /* 描述具体的class类型,值是type_ids的一个index,值必须是一个class类型,不能是数组或者基本类型 */
//u4 accessFlags; /* 描述class的访问类型,如public,final,static等 */
//u4 superclassIdx; /* 描述父类的类型,值必须是一个class类型,不能是数组或者基本类型 */
//u4 interfacesOff; /* 值为偏移地址,被指向的数据结构为type_list,class若没有interfaces,值为0 */
//u4 sourceFileIdx; /* 表示源代码文件的信息,值为string_ids的一个index。若此项信息丢失,此项赋值为NO_INDEX=0xFFFFFFFF */
//u4 annotationsOff; /* 值为偏移地址,指向的内容是该class的注解,位置在data区,格式为annotations_directory_item,若没有此项,值为0 */
//u4 classDataOff; /* 值为偏移地址,指向的内容是该class的使用到的数据,位置在data区,格式为class_data_item。无偶没有此项,则值为0 */
//u4 staticValuesOff; /* 值为偏移地址,指向data区里的一个列表,格式为encoded_array_item。若没有此项,值为0. */
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct class_def_item_list dex_class_defs\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->classDefsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,存储类的信息");
//转为DexMethodId结构体
DexClassDef *dexClassDef = (DexClassDef*)(fp + dex->pHeader->classDefsOff);
for (int i = 0; i < dex->pHeader->classDefsSize; ++i) {
printf("\n\tstruct class_def_item class_def[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexClassDef->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx\t\t--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
printf("\n\t\taccessFlags\t\t-->\t%x",dexClassDef->accessFlags);
//通过类型去寻找
const u1* superclassIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexClassDef->superclassIdx))];
//解码
readUnsignedLeb128(&superclassIdx_stringdata);
printf("\n\t\tsuperclassIdx\t--> ");
while(*superclassIdx_stringdata != '\0')
{
printf("%c",(*superclassIdx_stringdata));
superclassIdx_stringdata++;
}
printf("\n\t\tinterfacesOff\t-->\t%d",dexClassDef->interfacesOff);
if (dexClassDef->sourceFileIdx == -1)
{
printf("\n\t\tsourceFileIdx\t-->\tNO_INDEX");
}
printf("\n\t\tannotationsOff\t-->\t%d",dexClassDef->annotationsOff);
printf("\n\t\tclassDataOff\t-->\t%d",dexClassDef->classDataOff);
printf("\n\t\tstaticValuesOff\t-->\t%d",dexClassDef->staticValuesOff);
dexClassDef++;
}
}输出:
010:
代码写的比较乱,在这次学习中收获挺多的..
各位大神看完了有什么错的那啥,,轻点,,
u4 fileSize; //整个文件的长度,单位为字节,包括所有的内容
553820个字节大小
表示 DexHeader 头结构的大小,占用4个字节。这里可以看到它一共占用了112个字节,112对应的16进制数为70h
u4 headerSize; //默认是0x70个字节
u4 endianTag; //大小端标签,标准.dex文件为小端,此项一般固定为0x12345678常量
0
当多个class文件被编译到一个dex文件是,他们会用到link_size和link_off,通常为0
u4 linkSize; //链接数据的大小
u4 linkOff; //链接数据的偏移值
mapOff字段了,它指定了 DexMapList 的文件偏移
u4 mapOff; //map item的偏移地址,该item属于data区里的内容,值要大于等于dataOff的大小
stringIdsSize代表全dex文件的字符串的个数
stringIdsOff 代表全dex文件的字符串的偏移
u4 stringIdsSize; //DEX中用到的所有字符串内容的大小*
u4 stringIdsOff; //DEX中用到的所有字符串内容的偏移量
有了这个知识 可以尝试分析第一个字符串
已经找到第一个字符串的偏移是6e72c
那么也就找到了 第一个字符串的值 虽然看不明显但确实如此
以上的2个问题会在解析中给出答案!
这指出了type类型的偏移和type的个数
u4 typeIdsSize; //DEX中类型数据结构的大小
u4 typeIdsOff; //DEX中类型数据结构的偏移值
略...
u4 protoIdsSize; //DEX中的元数据信息数据结构的大小
u4 protoIdsOff; //DEX中的元数据信息数据结构的偏移值
u4 fieldIdsSize; //DEX中字段信息数据结构的大小
u4 fieldIdsOff; //DEX中字段信息数据结构的偏移值
u4 methodIdsSize; //DEX中方法信息数据结构的大小
u4 methodIdsOff; //DEX中方法信息数据结构的偏移值
u4 classDefsSize; //DEX中的类信息数据结构的大小
u4 classDefsOff; //DEX中的类信息数据结构的偏移值
u4 dataSize; //DEX中数据区域的结构信息的大小
u4 dataOff; //DEX中数据区域的结构信息的偏移值
1.1、解析DexHeader
那么就开始动手写的代码来解析吧~~
用的Clion编译器
1.
首先 先写个一个读取文件的方法
char* Read_File(string file_Path) {
filebuf *pbuf;
ifstream filestr;
long size;
char *buffer;
// 要读入整个文件,必须采用二进制打开
filestr.open(file_Path, ios::binary);
// 获取filestr对应buffer对象的指针
pbuf = filestr.rdbuf();
// 调用buffer对象方法获取文件大小
size = pbuf->pubseekoff(0, ios::end, ios::in);
pbuf->pubseekpos(0, ios::in);
// 分配内存空间
buffer = new char[size];
// 获取文件内容
pbuf->sgetn(buffer, size);
filestr.close();
// 输出到标准输出
//cout.write (buffer,size);
// delete []buffer;
return buffer;
}
2.
main:
//得到文件内存地址指针
char* fp = Read_File("/home/zlq/baidunetdiskdownload/android/classes.dex");
//强转为DexFile指针
DexFile *dex = (DexFile*)&fp;
//解析struct header_item dex_header
Read_DexHeader(dex->pHeader);
3.
写的比较拙劣,,,,
/**
* 实现方法
* @param dexHeader
*/
void Read_DexHeader(DexHeader* dexHeader)
{
//struct header_item dex_header
printf("struct header_item dex_header\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t0x0");
printf("\t\t\t\t0x%x", (unsigned int)sizeof(DexHeader));
printf("\t\tDEX 文件头,记录了一些当前文件的信息以及其他数据结构在文件中的偏移量");
printf("\n\tmagic\t\t\t\t\t\t\t\t");
char* magic = (char*)dexHeader->magic;
while(*magic != '\0')
{
if(*magic != '\n')
{
printf("%c ",(*magic));
}
magic++;
}
printf("\t\t\t\t\t\t\t\t\t\t0x0\t\t\t\t0x%x\t\t\t取值必须是字符串 \"dex\\n035\\0\" 或者字节byte数组 {0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00}",
(unsigned int)sizeof(dexHeader->magic));
printf("\n\tchecksum\t\t\t\t\t\t\t0x%X\t\t\t\t\t\t\t\t\t\t\t0x%x\t\t\t\t0x%x\t\t\t文件内容的校验和,不包括magic和自己,主要用于检查文件是否损坏"
,dexHeader->checksum
,(unsigned int)sizeof(dexHeader->magic)
,(unsigned int)sizeof(dexHeader->checksum));
.... 略
输出
通过对比分析是一样的
这个比较简单,用结构指针接受一下就行了 只是输出有点麻烦
2、 DexStringId
2.0、理解DexStringId
DEX中所有的字符串存储在这里
DexStringId* pStringIds; //数组,元素类型为string_id_item,存储字符串相关的信息
进去看看此结构!
它只有一个字段,那么它是如何解析dex字符串呢?
/*
* Direct-mapped "string_id_item".
*/
struct DexStringId {
//用于指明 string_data_item 位置文件的位置
u4 stringDataOff; /* file offset to string_data_item */
};首先要知道的是它是一个数组类型,数组的大小取决于
DexHeader->stringIdsSize
那么就很好理解了,上面提示 一共 有3619个 字符串
解析主要靠DexHeader中的stringIdsSize和stringIdsOff来解析
2.0、解析DexStringId
又开始写代码了
void Read_DexStringId(char* fp) {
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct string_id_list dex_string_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->stringIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexStringId));
printf("\t\t\t数组,元素类型为string_id_item,存储字符串相关的信息");
//拿到字符串的偏移
int *p2 = (int*)(fp + dex->pHeader->stringIdsOff);
////stringIdsSize --> DEX中用到的所有字符串内容的大小
for (int i = 0; i < dex->pHeader->stringIdsSize; ++i) {
printf("\n\tstruct string_id_item string_id[%d]:",i);
// 文件首地址+字符串偏移就是字符串存放的位置的第一个数组
const u1* stringdata = (u1*)fp+*p2;
//解码
/*
* dex文件里采用了变长方式表示字符串长度。一个字符串的长度可能是一个字节(小于256)或者4个字节(1G大小以上)。字符串的长度大多数都是小于 256个字节,因此需要使用一种编码,既可以表示一个字节的长度,也可以表示4个字节的长度,并且1个字节的长度占绝大多数。能满足这种表示的编码方式有很多,但dex文件里采用的是uleb128方式。leb128编码是一种变长编码,每个字节采用7位来表达原来的数据,最高位用来表示是否有后继字节。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高位为 0 。每个 Byte 的其余 Bit 用来表示数据
*/
readUnsignedLeb128(&stringdata);
//转码后该字符串为 内存数据为 \0 时 则结束
while(*stringdata != '\0')
{
//换行
if((*stringdata) != '\a' && (*stringdata) != '\b' &&(*stringdata) != '\t' && (*stringdata) != '\n' && (*stringdata) != '\v' && (*stringdata) != '\r' && (*stringdata) != '\f' )
{
printf("%c",(*stringdata));
}
//printf("%c",(*stringdata));
stringdata++;
}
p2++;
}
}
其中一部分的输出:
010:
总结:
* dex->pHeader->stringIdsOff 存储了整个dex的字符串的偏移的首地址 是一个数组类型
* dex->pHeader->stringIdsSize 存储字符串的个数
* 字符串偏移指向的地址的内容通过 readUnsignedLeb128 解码 字符串的长度通过判断'\0' 即可
编码:
LEB128即"Little-Endian Base 128",基于128的小印第安序编码格式,是对任意有符号或者无符号整型数的可变长度的编码。
也即,用LEB128编码的正数,会根据数字的大小改变所占字节数。在android的.dex文件中,他只用来编码32bits的整型数。
格式:
图只是指示性的用两个字节表示。编码的每个字节有效部分只有低7bits,每个字节的最高bit用来指示是否是最后一个字节。
非最高字节的bit7为0
最高字节的bit7为1
将leb128编码的数字转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
比如:
LEB128编码的0x02b0 ---> 转换后的数字0x0130
转换过程:
0x02b0 ---> 0000 0010 1011 0000 -->去除最高位--> 000 0010 011 0000 -->按4bits重排 --> 00 0001 0011 0000 --> 0x130
引用 https://blog.csdn.net/Roland_Sun/article/details/46708061
3、DexTypeId
3.0、理解DexTypeId
* type_ids 区索引了 .dex 文件里的所有数据类型 ,包括 class 类型 ,数组类型(array types)和基本类型(primitive types) 。 本区域里的元素格式为type_ids_item
* type_ids_item 里面 descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串 。
DexTypeId* pTypeIds; //数组,存储类型相关的信息
看结构
他也是一个字段,且看如何分析它
注意是一个数组的类型
/*
* Direct-mapped "type_id_item".
*/
struct DexTypeId {
u4 descriptorIdx; /* 指向string_ids的索引 */
};
同时 还有2个很重要的字段在DexHeader中typeIdsSize和typeIdsOff 同样代表类型的偏移和大小.
先来分析第一个type:
得知第一个type所在位置是 00 00 38 FC
010
得到的值是 0x19F
根据描述 /* 指向string_ids的索引 */ 知道这个值是字符串偏移的索引
0x19F = 415
恰好是第一个类型的值 : B byte
如此就分析出第一个类型的位置和来源了
3.0、解析DexTypeId
又开始写代码:
void Read_DexTypeId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct struct type_id_list dex_type_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->typeIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexTypeId));
printf("\t\t\t数组,存储类型相关的信息\n");
//拿到类型的偏移
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
for (int i = 0; i < dex->pHeader->typeIdsSize; ++i) {
printf("\n\tstruct type_id_list dex_type_ids[%d]:",i);
//先拿到字符串的偏移
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
//再根据类型的偏移去寻找字符串
const u1* stringdata = (u1*)fp+stringIdsOff[(*typeIdsOff)];
//解码
readUnsignedLeb128(&stringdata);
while(*stringdata != '\0')
{
printf("%c",(*stringdata));
stringdata++;
}
//自加 获取下一个指针 int型指针自加 base += 1
typeIdsOff++;
}
}
输出:
010:
总结:
descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串
字符串指针[descriptor_idx地址内的值] = descriptor_idx值
4、DexFieldId
4.0、理解DexFieldId
大意:
DexFieldId* pFieldIds; //数组,存储成员变量信息,包括变量名和类型等
具体结构:
struct DexFieldId {
u2 classIdx; /* field所属的class类型,class_idx的值时type_ids的一个index,指向所属的类 */
u2 typeIdx; /* field的类型,值是type_ids的一个index */
u4 nameIdx; /* field的名称,它的值是string_ids的一个index */
};
仍然从header看起 重要的数据还是保存在头部
继续从010中尝试分析:
那么来到 824C
之前分析过type 这次 分析结构中的 type_idx
上图可见 type_idx的地址的值内容为 0x1D 也就是 29
可以看到 他们的值是一致的!
另外2个原理一直,可以自行分析
截图截多了!不好意思!
4.1、解析DexFieldId
又开始写代码
比较麻烦的是取值的过程需要通过其他属性来取值
void Read_DexFieldId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct field_id_list dex_field_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->fieldIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexFieldId));
printf("\t\t\t数组,存储类的相关的信息");
//转为DexFieldId结构体
DexFieldId *dexFieldId = (DexFieldId*)(fp + dex->pHeader->fieldIdsOff);
for (int i = 0; i < dex->pHeader->fieldIdsSize; ++i) {
printf("\n\tstruct field_id_item field_id[%d]",i);
/**
* 重点:
* 要想找到field_id的typeIdx对应位置的值 要先找到 typeIdsOff偏移地址+typeIdx等于string_ids的索引,再通过string_ids来寻找值
*
* [类型偏移首地址+typeIdx索引] = 字符串所在的索引位置
* 字符串偏移首地址[字符串所在的索引位置] = [类型偏移首地址+typeIdx索引]的具体值
*/
//拿到类型的偏移首地址
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
//拿到字符串的偏移首地址
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
//类型偏移地址+索引=字符串索引
//字符串偏移+字符串索引=typeIdx位置具体的值
const u1* typeIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexFieldId->typeIdx))];
//解码
readUnsignedLeb128(&typeIdx_stringdata);
printf("\n\t\ttypeIdx --> ");
while(*typeIdx_stringdata != '\0')
{
printf("%c",(*typeIdx_stringdata));
typeIdx_stringdata++;
}
//u2 classIdx; /* field所属的class类型,class_idx的值时type_ids的一个index,指向所属的类 */
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexFieldId->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
//u4 nameIdx; /* field的名称,它的值是string_ids的一个index */
const u1* nameIdx_stringdata = (u1*)fp+stringIdsOff[(dexFieldId->nameIdx)];
//解码
readUnsignedLeb128(&nameIdx_stringdata);
printf("\n\t\tnameIdx --> ");
while(*nameIdx_stringdata != '\0')
{
printf("%c",(*nameIdx_stringdata));
nameIdx_stringdata++;
}
dexFieldId++;
}
}
输出
010
5、DexMethodId
5.0、理解DexMethodId
DexMethodId* pMethodIds; //数组,存储成员函数信息包括函数名 参数和返回值类型<br>
查看具体结构
描述的比较清晰
struct DexMethodId {
u2 classIdx; /* method所属的class类型,class_idx的值是type_ids的一个index,必须指向一个class类型 */
u2 protoIdx; /* method的原型,指向proto_ids的一个index */
u4 nameIdx; /* method的名称,值为string_ids的一个index */
};
可以自己尝试手动分析了,这里就不过多的演示了..之前演示很多次了
5.1、解析DexMethodId
又开始写代码了
void Read_DexMethodId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct method_id_list dex_method_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->methodIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,存储成员函数信息包括函数名 参数和返回值类型");
//转为DexMethodId结构体
DexMethodId *dexMethodId = (DexMethodId*)(fp + dex->pHeader->methodIdsOff);
for (int i = 0; i < dex->pHeader->methodIdsSize; ++i) {
printf("\n\tstruct method_id_item method_id[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *protoIdsOff = (int*)(fp + dex->pHeader->protoIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexMethodId->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
//method的原型,指向proto_ids的一个index
DexProtoId* dexProtoId = (DexProtoId*) protoIdsOff+dexMethodId->protoIdx;
const u1* protoIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexProtoId->returnTypeIdx))];
readUnsignedLeb128(&protoIdx_stringdata);
printf("\n\t\tprotoIdx--> ");
while(*protoIdx_stringdata != '\0')
{
printf("%c",(*protoIdx_stringdata));
protoIdx_stringdata++;
}
const u1* nameIdx_stringdata = (u1*)fp+stringIdsOff[dexMethodId->nameIdx];
//解码
readUnsignedLeb128(&nameIdx_stringdata);
printf("\n\t\tnameIdx --> ");
while(*nameIdx_stringdata != '\0')
{
printf("%c",(*nameIdx_stringdata));
nameIdx_stringdata++;
}
dexMethodId++;
}
}
输出:
010
6、DexProtoId
6.0、理解DexProtoId
DexProtoId* pProtoIds; //数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表
具体结构
struct DexProtoId {
u4 shortyIdx; /* 值为一个string_ids的index号,用来说明该method原型 */
u4 returnTypeIdx; /* 值为一个type_ids的index,表示该method原型的返回值类型 */
u4 parametersOff; /* 指定method原型的参数列表type_list,若method没有参数,则值为0. 参数的格式是type_list */
};
6.0、解析DexProtoId
void Read_DexProtoId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct proto_id_list dex_proto_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->protoIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表");
//转为DexMethodId结构体
DexProtoId *dexProtoId = (DexProtoId*)(fp + dex->pHeader->protoIdsOff);
for (int i = 0; i < dex->pHeader->protoIdsSize; ++i) {
printf("\n\tstruct proto_id_item proto_id[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* shortyIdx_stringdata = (u1*)fp+stringIdsOff[dexProtoId->shortyIdx];
//解码
readUnsignedLeb128(&shortyIdx_stringdata);
printf("\n\t\tshortyIdx--> ");
while(*shortyIdx_stringdata != '\0')
{
printf("%c",(*shortyIdx_stringdata));
shortyIdx_stringdata++;
}
const u1* returnTypeIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexProtoId->returnTypeIdx))];
readUnsignedLeb128(&returnTypeIdx_stringdata);
printf("\n\t\tprotoIdx--> ");
while(*returnTypeIdx_stringdata != '\0')
{
printf("%c",(*returnTypeIdx_stringdata));
returnTypeIdx_stringdata++;
}
printf("\n\t\tparametersOff--> %d",dexProtoId->parametersOff);
dexProtoId++;
}
}
输出:
010:
7、DexClassDef
7.0、理解DexClassDef
DexClassDef* pClassDefs; //数组,存储类的信息
结构体
struct DexClassDef {
u4 classIdx; /* 描述具体的class类型,值是type_ids的一个index,值必须是一个class类型,不能是数组或者基本类型 */
u4 accessFlags; /* 描述class的访问类型,如public,final,static等 */
u4 superclassIdx; /* 描述父类的类型,值必须是一个class类型,不能是数组雷兴国或者基本类型 */
u4 interfacesOff; /* 值为偏移地址,被指向的数据结构为type_list,class若没有interfaces,值为0 */
u4 sourceFileIdx; /* 表示源代码文件的信息,值为string_ids的一个index。若此项信息丢失,此项赋值为NO_INDEX=0xFFFFFFFF */
u4 annotationsOff; /* 值为偏移地址,指向的内容是该class的注解,位置在data区,格式为annotations_directory_item,若没有此项,值为0 */
u4 classDataOff; /* 值为偏移地址,指向的内容是该class的使用到的数据,位置在data区,格式为class_data_item。无偶没有此项,则值为0 */
u4 staticValuesOff; /* 值为偏移地址,指向data区里的一个列表,格式为encoded_array_item。若没有此项,值为0. */
};
解析:
void Read_DexClassDef(char* fp)
{
//u4 classIdx; /* 描述具体的class类型,值是type_ids的一个index,值必须是一个class类型,不能是数组或者基本类型 */
//u4 accessFlags; /* 描述class的访问类型,如public,final,static等 */
//u4 superclassIdx; /* 描述父类的类型,值必须是一个class类型,不能是数组或者基本类型 */
//u4 interfacesOff; /* 值为偏移地址,被指向的数据结构为type_list,class若没有interfaces,值为0 */
//u4 sourceFileIdx; /* 表示源代码文件的信息,值为string_ids的一个index。若此项信息丢失,此项赋值为NO_INDEX=0xFFFFFFFF */
//u4 annotationsOff; /* 值为偏移地址,指向的内容是该class的注解,位置在data区,格式为annotations_directory_item,若没有此项,值为0 */
//u4 classDataOff; /* 值为偏移地址,指向的内容是该class的使用到的数据,位置在data区,格式为class_data_item。无偶没有此项,则值为0 */
//u4 staticValuesOff; /* 值为偏移地址,指向data区里的一个列表,格式为encoded_array_item。若没有此项,值为0. */
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct class_def_item_list dex_class_defs\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->classDefsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,存储类的信息");
//转为DexMethodId结构体
DexClassDef *dexClassDef = (DexClassDef*)(fp + dex->pHeader->classDefsOff);
for (int i = 0; i < dex->pHeader->classDefsSize; ++i) {
printf("\n\tstruct class_def_item class_def[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexClassDef->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx\t\t--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
printf("\n\t\taccessFlags\t\t-->\t%x",dexClassDef->accessFlags);
//通过类型去寻找
const u1* superclassIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexClassDef->superclassIdx))];
//解码
readUnsignedLeb128(&superclassIdx_stringdata);
printf("\n\t\tsuperclassIdx\t--> ");
while(*superclassIdx_stringdata != '\0')
{
printf("%c",(*superclassIdx_stringdata));
superclassIdx_stringdata++;
}
printf("\n\t\tinterfacesOff\t-->\t%d",dexClassDef->interfacesOff);
if (dexClassDef->sourceFileIdx == -1)
{
printf("\n\t\tsourceFileIdx\t-->\tNO_INDEX");
}
printf("\n\t\tannotationsOff\t-->\t%d",dexClassDef->annotationsOff);
printf("\n\t\tclassDataOff\t-->\t%d",dexClassDef->classDataOff);
printf("\n\t\tstaticValuesOff\t-->\t%d",dexClassDef->staticValuesOff);
dexClassDef++;
}
}输出:
010:
代码写的比较乱,在这次学习中收获挺多的..
各位大神看完了有什么错的那啥,,轻点,,
u4 headerSize; //默认是0x70个字节
u4 endianTag; //大小端标签,标准.dex文件为小端,此项一般固定为0x12345678常量
0
当多个class文件被编译到一个dex文件是,他们会用到link_size和link_off,通常为0
u4 linkSize; //链接数据的大小
u4 linkOff; //链接数据的偏移值
mapOff字段了,它指定了 DexMapList 的文件偏移
u4 mapOff; //map item的偏移地址,该item属于data区里的内容,值要大于等于dataOff的大小
stringIdsSize代表全dex文件的字符串的个数
stringIdsOff 代表全dex文件的字符串的偏移
u4 stringIdsSize; //DEX中用到的所有字符串内容的大小*
u4 stringIdsOff; //DEX中用到的所有字符串内容的偏移量
有了这个知识 可以尝试分析第一个字符串
已经找到第一个字符串的偏移是6e72c
那么也就找到了 第一个字符串的值 虽然看不明显但确实如此
以上的2个问题会在解析中给出答案!
这指出了type类型的偏移和type的个数
u4 typeIdsSize; //DEX中类型数据结构的大小
u4 typeIdsOff; //DEX中类型数据结构的偏移值
略...
u4 protoIdsSize; //DEX中的元数据信息数据结构的大小
u4 protoIdsOff; //DEX中的元数据信息数据结构的偏移值
u4 fieldIdsSize; //DEX中字段信息数据结构的大小
u4 fieldIdsOff; //DEX中字段信息数据结构的偏移值
u4 methodIdsSize; //DEX中方法信息数据结构的大小
u4 methodIdsOff; //DEX中方法信息数据结构的偏移值
u4 classDefsSize; //DEX中的类信息数据结构的大小
u4 classDefsOff; //DEX中的类信息数据结构的偏移值
u4 dataSize; //DEX中数据区域的结构信息的大小
u4 dataOff; //DEX中数据区域的结构信息的偏移值
1.1、解析DexHeader
那么就开始动手写的代码来解析吧~~
用的Clion编译器
1.
首先 先写个一个读取文件的方法
char* Read_File(string file_Path) {
filebuf *pbuf;
ifstream filestr;
long size;
char *buffer;
// 要读入整个文件,必须采用二进制打开
filestr.open(file_Path, ios::binary);
// 获取filestr对应buffer对象的指针
pbuf = filestr.rdbuf();
// 调用buffer对象方法获取文件大小
size = pbuf->pubseekoff(0, ios::end, ios::in);
pbuf->pubseekpos(0, ios::in);
// 分配内存空间
buffer = new char[size];
// 获取文件内容
pbuf->sgetn(buffer, size);
filestr.close();
// 输出到标准输出
//cout.write (buffer,size);
// delete []buffer;
return buffer;
}
2.
main:
//得到文件内存地址指针
char* fp = Read_File("/home/zlq/baidunetdiskdownload/android/classes.dex");
//强转为DexFile指针
DexFile *dex = (DexFile*)&fp;
//解析struct header_item dex_header
Read_DexHeader(dex->pHeader);
3.
写的比较拙劣,,,,
/**
* 实现方法
* @param dexHeader
*/
void Read_DexHeader(DexHeader* dexHeader)
{
//struct header_item dex_header
printf("struct header_item dex_header\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t0x0");
printf("\t\t\t\t0x%x", (unsigned int)sizeof(DexHeader));
printf("\t\tDEX 文件头,记录了一些当前文件的信息以及其他数据结构在文件中的偏移量");
printf("\n\tmagic\t\t\t\t\t\t\t\t");
char* magic = (char*)dexHeader->magic;
while(*magic != '\0')
{
if(*magic != '\n')
{
printf("%c ",(*magic));
}
magic++;
}
printf("\t\t\t\t\t\t\t\t\t\t0x0\t\t\t\t0x%x\t\t\t取值必须是字符串 \"dex\\n035\\0\" 或者字节byte数组 {0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00}",
(unsigned int)sizeof(dexHeader->magic));
printf("\n\tchecksum\t\t\t\t\t\t\t0x%X\t\t\t\t\t\t\t\t\t\t\t0x%x\t\t\t\t0x%x\t\t\t文件内容的校验和,不包括magic和自己,主要用于检查文件是否损坏"
,dexHeader->checksum
,(unsigned int)sizeof(dexHeader->magic)
,(unsigned int)sizeof(dexHeader->checksum));
.... 略
输出
通过对比分析是一样的
这个比较简单,用结构指针接受一下就行了 只是输出有点麻烦
2、 DexStringId
2.0、理解DexStringId
DEX中所有的字符串存储在这里
DexStringId* pStringIds; //数组,元素类型为string_id_item,存储字符串相关的信息
进去看看此结构!
它只有一个字段,那么它是如何解析dex字符串呢?
/*
* Direct-mapped "string_id_item".
*/
struct DexStringId {
//用于指明 string_data_item 位置文件的位置
u4 stringDataOff; /* file offset to string_data_item */
};首先要知道的是它是一个数组类型,数组的大小取决于
DexHeader->stringIdsSize
那么就很好理解了,上面提示 一共 有3619个 字符串
解析主要靠DexHeader中的stringIdsSize和stringIdsOff来解析
2.0、解析DexStringId
又开始写代码了
void Read_DexStringId(char* fp) {
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct string_id_list dex_string_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->stringIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexStringId));
printf("\t\t\t数组,元素类型为string_id_item,存储字符串相关的信息");
//拿到字符串的偏移
int *p2 = (int*)(fp + dex->pHeader->stringIdsOff);
////stringIdsSize --> DEX中用到的所有字符串内容的大小
for (int i = 0; i < dex->pHeader->stringIdsSize; ++i) {
printf("\n\tstruct string_id_item string_id[%d]:",i);
// 文件首地址+字符串偏移就是字符串存放的位置的第一个数组
const u1* stringdata = (u1*)fp+*p2;
//解码
/*
* dex文件里采用了变长方式表示字符串长度。一个字符串的长度可能是一个字节(小于256)或者4个字节(1G大小以上)。字符串的长度大多数都是小于 256个字节,因此需要使用一种编码,既可以表示一个字节的长度,也可以表示4个字节的长度,并且1个字节的长度占绝大多数。能满足这种表示的编码方式有很多,但dex文件里采用的是uleb128方式。leb128编码是一种变长编码,每个字节采用7位来表达原来的数据,最高位用来表示是否有后继字节。若第一个 Byte 的最高位为 1 ,则表示还需要下一个 Byte 来描述 ,直至最后一个 Byte 的最高位为 0 。每个 Byte 的其余 Bit 用来表示数据
*/
readUnsignedLeb128(&stringdata);
//转码后该字符串为 内存数据为 \0 时 则结束
while(*stringdata != '\0')
{
//换行
if((*stringdata) != '\a' && (*stringdata) != '\b' &&(*stringdata) != '\t' && (*stringdata) != '\n' && (*stringdata) != '\v' && (*stringdata) != '\r' && (*stringdata) != '\f' )
{
printf("%c",(*stringdata));
}
//printf("%c",(*stringdata));
stringdata++;
}
p2++;
}
}
其中一部分的输出:
010:
总结:
* dex->pHeader->stringIdsOff 存储了整个dex的字符串的偏移的首地址 是一个数组类型
* dex->pHeader->stringIdsSize 存储字符串的个数
* 字符串偏移指向的地址的内容通过 readUnsignedLeb128 解码 字符串的长度通过判断'\0' 即可
编码:
LEB128即"Little-Endian Base 128",基于128的小印第安序编码格式,是对任意有符号或者无符号整型数的可变长度的编码。
也即,用LEB128编码的正数,会根据数字的大小改变所占字节数。在android的.dex文件中,他只用来编码32bits的整型数。
格式:
图只是指示性的用两个字节表示。编码的每个字节有效部分只有低7bits,每个字节的最高bit用来指示是否是最后一个字节。
非最高字节的bit7为0
最高字节的bit7为1
将leb128编码的数字转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
比如:
LEB128编码的0x02b0 ---> 转换后的数字0x0130
转换过程:
0x02b0 ---> 0000 0010 1011 0000 -->去除最高位--> 000 0010 011 0000 -->按4bits重排 --> 00 0001 0011 0000 --> 0x130
引用 https://blog.csdn.net/Roland_Sun/article/details/46708061
3、DexTypeId
3.0、理解DexTypeId
* type_ids 区索引了 .dex 文件里的所有数据类型 ,包括 class 类型 ,数组类型(array types)和基本类型(primitive types) 。 本区域里的元素格式为type_ids_item
* type_ids_item 里面 descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串 。
DexTypeId* pTypeIds; //数组,存储类型相关的信息
看结构
他也是一个字段,且看如何分析它
注意是一个数组的类型
/*
* Direct-mapped "type_id_item".
*/
struct DexTypeId {
u4 descriptorIdx; /* 指向string_ids的索引 */
};
同时 还有2个很重要的字段在DexHeader中typeIdsSize和typeIdsOff 同样代表类型的偏移和大小.
先来分析第一个type:
得知第一个type所在位置是 00 00 38 FC
010
得到的值是 0x19F
根据描述 /* 指向string_ids的索引 */ 知道这个值是字符串偏移的索引
0x19F = 415
恰好是第一个类型的值 : B byte
如此就分析出第一个类型的位置和来源了
3.0、解析DexTypeId
又开始写代码:
void Read_DexTypeId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct struct type_id_list dex_type_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->typeIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexTypeId));
printf("\t\t\t数组,存储类型相关的信息\n");
//拿到类型的偏移
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
for (int i = 0; i < dex->pHeader->typeIdsSize; ++i) {
printf("\n\tstruct type_id_list dex_type_ids[%d]:",i);
//先拿到字符串的偏移
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
//再根据类型的偏移去寻找字符串
const u1* stringdata = (u1*)fp+stringIdsOff[(*typeIdsOff)];
//解码
readUnsignedLeb128(&stringdata);
while(*stringdata != '\0')
{
printf("%c",(*stringdata));
stringdata++;
}
//自加 获取下一个指针 int型指针自加 base += 1
typeIdsOff++;
}
}
输出:
010:
总结:
descriptor_idx 的值的意思 ,是 string_ids 里的 index 序号 ,是用来描述此type 的字符串
字符串指针[descriptor_idx地址内的值] = descriptor_idx值
4、DexFieldId
4.0、理解DexFieldId
大意:
DexFieldId* pFieldIds; //数组,存储成员变量信息,包括变量名和类型等
具体结构:
struct DexFieldId {
u2 classIdx; /* field所属的class类型,class_idx的值时type_ids的一个index,指向所属的类 */
u2 typeIdx; /* field的类型,值是type_ids的一个index */
u4 nameIdx; /* field的名称,它的值是string_ids的一个index */
};
仍然从header看起 重要的数据还是保存在头部
继续从010中尝试分析:
那么来到 824C
之前分析过type 这次 分析结构中的 type_idx
上图可见 type_idx的地址的值内容为 0x1D 也就是 29
可以看到 他们的值是一致的!
另外2个原理一直,可以自行分析
截图截多了!不好意思!
4.1、解析DexFieldId
又开始写代码
比较麻烦的是取值的过程需要通过其他属性来取值
void Read_DexFieldId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct field_id_list dex_field_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->fieldIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexFieldId));
printf("\t\t\t数组,存储类的相关的信息");
//转为DexFieldId结构体
DexFieldId *dexFieldId = (DexFieldId*)(fp + dex->pHeader->fieldIdsOff);
for (int i = 0; i < dex->pHeader->fieldIdsSize; ++i) {
printf("\n\tstruct field_id_item field_id[%d]",i);
/**
* 重点:
* 要想找到field_id的typeIdx对应位置的值 要先找到 typeIdsOff偏移地址+typeIdx等于string_ids的索引,再通过string_ids来寻找值
*
* [类型偏移首地址+typeIdx索引] = 字符串所在的索引位置
* 字符串偏移首地址[字符串所在的索引位置] = [类型偏移首地址+typeIdx索引]的具体值
*/
//拿到类型的偏移首地址
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
//拿到字符串的偏移首地址
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
//类型偏移地址+索引=字符串索引
//字符串偏移+字符串索引=typeIdx位置具体的值
const u1* typeIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexFieldId->typeIdx))];
//解码
readUnsignedLeb128(&typeIdx_stringdata);
printf("\n\t\ttypeIdx --> ");
while(*typeIdx_stringdata != '\0')
{
printf("%c",(*typeIdx_stringdata));
typeIdx_stringdata++;
}
//u2 classIdx; /* field所属的class类型,class_idx的值时type_ids的一个index,指向所属的类 */
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexFieldId->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
//u4 nameIdx; /* field的名称,它的值是string_ids的一个index */
const u1* nameIdx_stringdata = (u1*)fp+stringIdsOff[(dexFieldId->nameIdx)];
//解码
readUnsignedLeb128(&nameIdx_stringdata);
printf("\n\t\tnameIdx --> ");
while(*nameIdx_stringdata != '\0')
{
printf("%c",(*nameIdx_stringdata));
nameIdx_stringdata++;
}
dexFieldId++;
}
}
输出
010
5、DexMethodId
5.0、理解DexMethodId
DexMethodId* pMethodIds; //数组,存储成员函数信息包括函数名 参数和返回值类型<br>
查看具体结构
描述的比较清晰
struct DexMethodId {
u2 classIdx; /* method所属的class类型,class_idx的值是type_ids的一个index,必须指向一个class类型 */
u2 protoIdx; /* method的原型,指向proto_ids的一个index */
u4 nameIdx; /* method的名称,值为string_ids的一个index */
};
可以自己尝试手动分析了,这里就不过多的演示了..之前演示很多次了
5.1、解析DexMethodId
又开始写代码了
void Read_DexMethodId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct method_id_list dex_method_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->methodIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,存储成员函数信息包括函数名 参数和返回值类型");
//转为DexMethodId结构体
DexMethodId *dexMethodId = (DexMethodId*)(fp + dex->pHeader->methodIdsOff);
for (int i = 0; i < dex->pHeader->methodIdsSize; ++i) {
printf("\n\tstruct method_id_item method_id[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *protoIdsOff = (int*)(fp + dex->pHeader->protoIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexMethodId->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
//method的原型,指向proto_ids的一个index
DexProtoId* dexProtoId = (DexProtoId*) protoIdsOff+dexMethodId->protoIdx;
const u1* protoIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexProtoId->returnTypeIdx))];
readUnsignedLeb128(&protoIdx_stringdata);
printf("\n\t\tprotoIdx--> ");
while(*protoIdx_stringdata != '\0')
{
printf("%c",(*protoIdx_stringdata));
protoIdx_stringdata++;
}
const u1* nameIdx_stringdata = (u1*)fp+stringIdsOff[dexMethodId->nameIdx];
//解码
readUnsignedLeb128(&nameIdx_stringdata);
printf("\n\t\tnameIdx --> ");
while(*nameIdx_stringdata != '\0')
{
printf("%c",(*nameIdx_stringdata));
nameIdx_stringdata++;
}
dexMethodId++;
}
}
输出:
010
6、DexProtoId
6.0、理解DexProtoId
DexProtoId* pProtoIds; //数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表
具体结构
struct DexProtoId {
u4 shortyIdx; /* 值为一个string_ids的index号,用来说明该method原型 */
u4 returnTypeIdx; /* 值为一个type_ids的index,表示该method原型的返回值类型 */
u4 parametersOff; /* 指定method原型的参数列表type_list,若method没有参数,则值为0. 参数的格式是type_list */
};
6.0、解析DexProtoId
void Read_DexProtoId(char* fp)
{
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct proto_id_list dex_proto_ids\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->protoIdsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,函数原型数据索引,记录了方法声明的字符串,返回类型和参数列表");
//转为DexMethodId结构体
DexProtoId *dexProtoId = (DexProtoId*)(fp + dex->pHeader->protoIdsOff);
for (int i = 0; i < dex->pHeader->protoIdsSize; ++i) {
printf("\n\tstruct proto_id_item proto_id[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* shortyIdx_stringdata = (u1*)fp+stringIdsOff[dexProtoId->shortyIdx];
//解码
readUnsignedLeb128(&shortyIdx_stringdata);
printf("\n\t\tshortyIdx--> ");
while(*shortyIdx_stringdata != '\0')
{
printf("%c",(*shortyIdx_stringdata));
shortyIdx_stringdata++;
}
const u1* returnTypeIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexProtoId->returnTypeIdx))];
readUnsignedLeb128(&returnTypeIdx_stringdata);
printf("\n\t\tprotoIdx--> ");
while(*returnTypeIdx_stringdata != '\0')
{
printf("%c",(*returnTypeIdx_stringdata));
returnTypeIdx_stringdata++;
}
printf("\n\t\tparametersOff--> %d",dexProtoId->parametersOff);
dexProtoId++;
}
}
输出:
010:
7、DexClassDef
7.0、理解DexClassDef
DexClassDef* pClassDefs; //数组,存储类的信息
结构体
struct DexClassDef {
u4 classIdx; /* 描述具体的class类型,值是type_ids的一个index,值必须是一个class类型,不能是数组或者基本类型 */
u4 accessFlags; /* 描述class的访问类型,如public,final,static等 */
u4 superclassIdx; /* 描述父类的类型,值必须是一个class类型,不能是数组雷兴国或者基本类型 */
u4 interfacesOff; /* 值为偏移地址,被指向的数据结构为type_list,class若没有interfaces,值为0 */
u4 sourceFileIdx; /* 表示源代码文件的信息,值为string_ids的一个index。若此项信息丢失,此项赋值为NO_INDEX=0xFFFFFFFF */
u4 annotationsOff; /* 值为偏移地址,指向的内容是该class的注解,位置在data区,格式为annotations_directory_item,若没有此项,值为0 */
u4 classDataOff; /* 值为偏移地址,指向的内容是该class的使用到的数据,位置在data区,格式为class_data_item。无偶没有此项,则值为0 */
u4 staticValuesOff; /* 值为偏移地址,指向data区里的一个列表,格式为encoded_array_item。若没有此项,值为0. */
};
解析:
void Read_DexClassDef(char* fp)
{
//u4 classIdx; /* 描述具体的class类型,值是type_ids的一个index,值必须是一个class类型,不能是数组或者基本类型 */
//u4 accessFlags; /* 描述class的访问类型,如public,final,static等 */
//u4 superclassIdx; /* 描述父类的类型,值必须是一个class类型,不能是数组或者基本类型 */
//u4 interfacesOff; /* 值为偏移地址,被指向的数据结构为type_list,class若没有interfaces,值为0 */
//u4 sourceFileIdx; /* 表示源代码文件的信息,值为string_ids的一个index。若此项信息丢失,此项赋值为NO_INDEX=0xFFFFFFFF */
//u4 annotationsOff; /* 值为偏移地址,指向的内容是该class的注解,位置在data区,格式为annotations_directory_item,若没有此项,值为0 */
//u4 classDataOff; /* 值为偏移地址,指向的内容是该class的使用到的数据,位置在data区,格式为class_data_item。无偶没有此项,则值为0 */
//u4 staticValuesOff; /* 值为偏移地址,指向data区里的一个列表,格式为encoded_array_item。若没有此项,值为0. */
DexFile *dex = (DexFile*)&fp;
printf("\n\nstruct class_def_item_list dex_class_defs\t%d\t\t\t\t\t\t\t\t\t\t\t\t0x%x", dex->pHeader->classDefsSize,(unsigned int) sizeof(DexHeader));
printf("\t\t\t0x%x", (unsigned int) sizeof(DexMethodId));
printf("\t\t\t数组,存储类的信息");
//转为DexMethodId结构体
DexClassDef *dexClassDef = (DexClassDef*)(fp + dex->pHeader->classDefsOff);
for (int i = 0; i < dex->pHeader->classDefsSize; ++i) {
printf("\n\tstruct class_def_item class_def[%d]", i);
int *typeIdsOff = (int*)(fp + dex->pHeader->typeIdsOff);
int *stringIdsOff = (int*)(fp + dex->pHeader->stringIdsOff);
const u1* classIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexClassDef->classIdx))];
//解码
readUnsignedLeb128(&classIdx_stringdata);
printf("\n\t\tclassIdx\t\t--> ");
while(*classIdx_stringdata != '\0')
{
printf("%c",(*classIdx_stringdata));
classIdx_stringdata++;
}
printf("\n\t\taccessFlags\t\t-->\t%x",dexClassDef->accessFlags);
//通过类型去寻找
const u1* superclassIdx_stringdata = (u1*)fp+stringIdsOff[(*(typeIdsOff+dexClassDef->superclassIdx))];
//解码
readUnsignedLeb128(&superclassIdx_stringdata);
printf("\n\t\tsuperclassIdx\t--> ");
while(*superclassIdx_stringdata != '\0')
{
printf("%c",(*superclassIdx_stringdata));
superclassIdx_stringdata++;
}
printf("\n\t\tinterfacesOff\t-->\t%d",dexClassDef->interfacesOff);
if (dexClassDef->sourceFileIdx == -1)
{
printf("\n\t\tsourceFileIdx\t-->\tNO_INDEX");
}
printf("\n\t\tannotationsOff\t-->\t%d",dexClassDef->annotationsOff);
printf("\n\t\tclassDataOff\t-->\t%d",dexClassDef->classDataOff);
printf("\n\t\tstaticValuesOff\t-->\t%d",dexClassDef->staticValuesOff);
dexClassDef++;
}
}输出:
010:
代码写的比较乱,在这次学习中收获挺多的..
各位大神看完了有什么错的那啥,,轻点,,
u4 endianTag; //大小端标签,标准.dex文件为小端,此项一般固定为0x12345678常量
[培训]内核驱动高级班,冲击BAT一流互联网大厂工作,每周日13:00-18:00直播授课
最后于 2019-11-1 13:02
被iio编辑
,原因: 代码排版问题

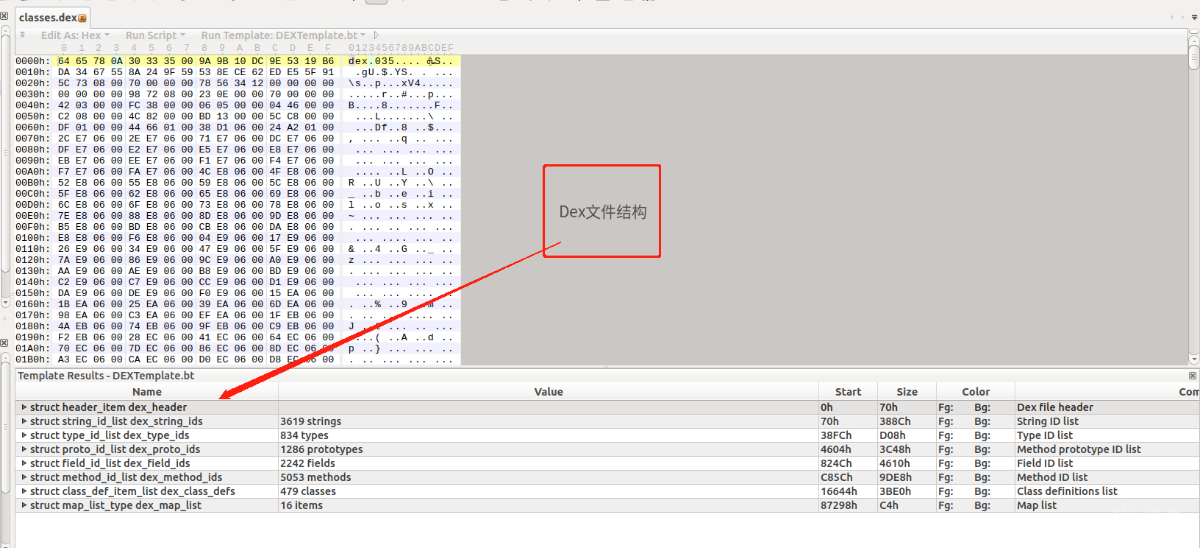
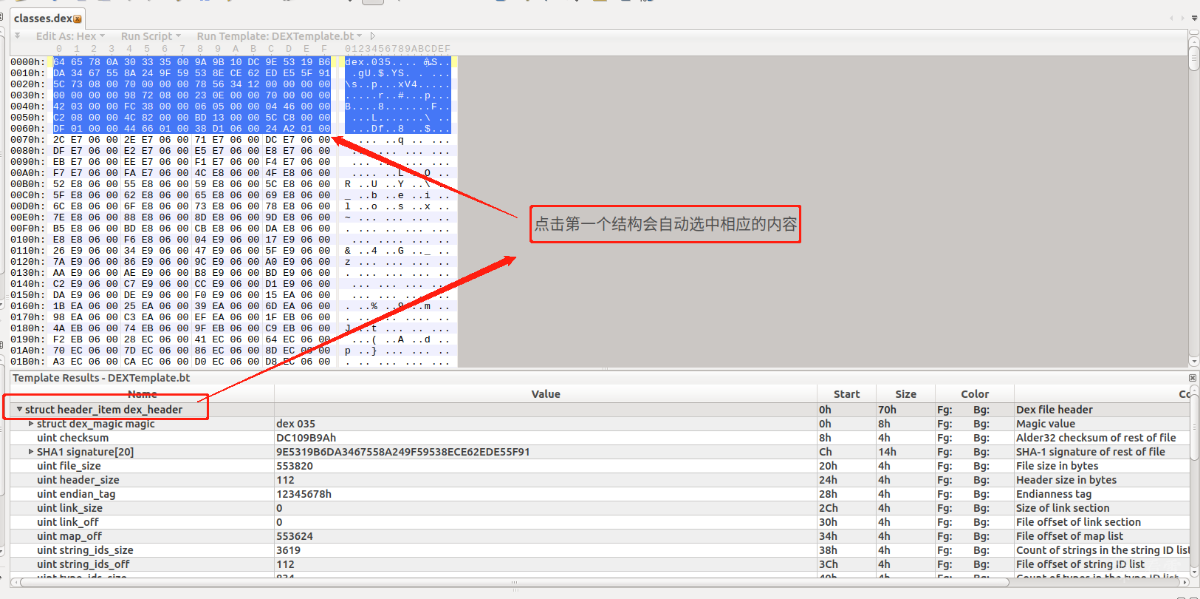
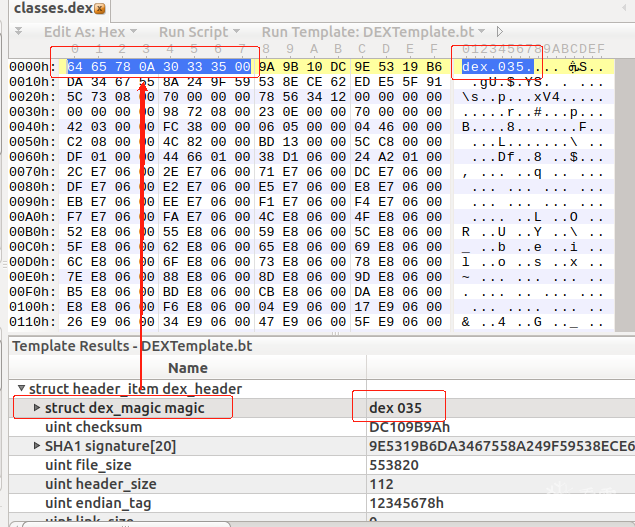

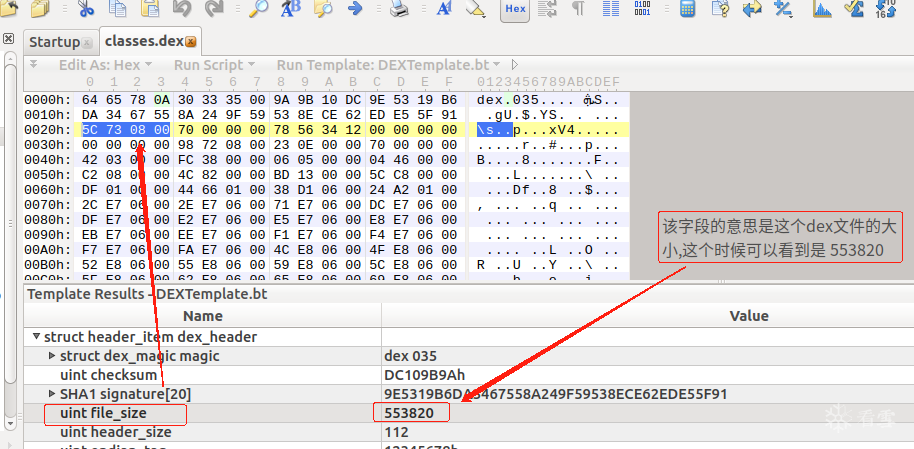
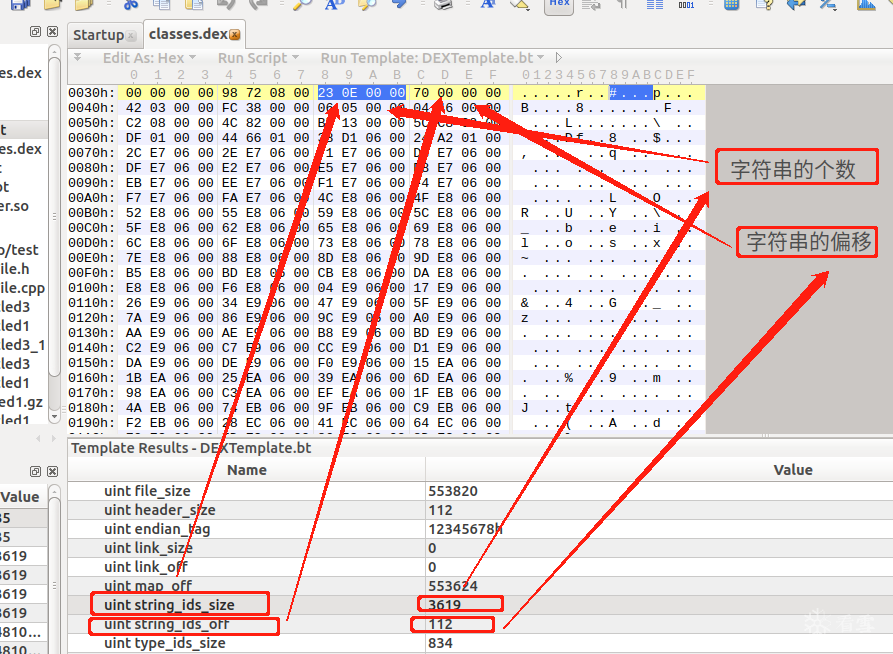


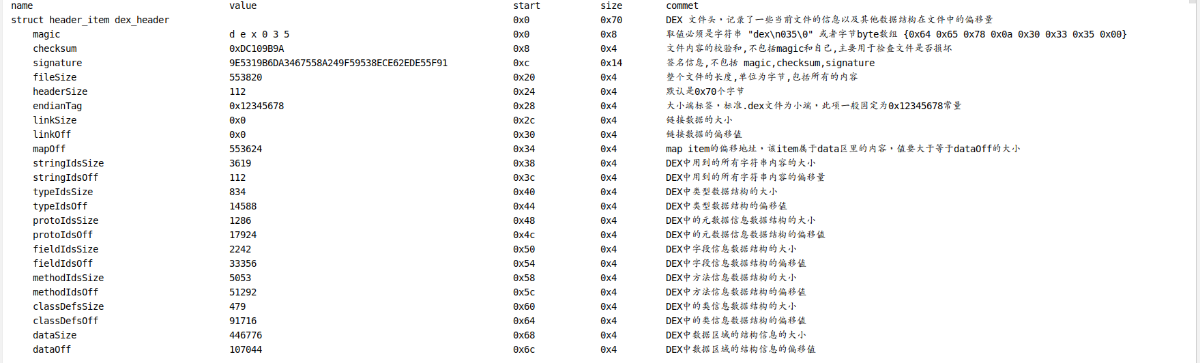


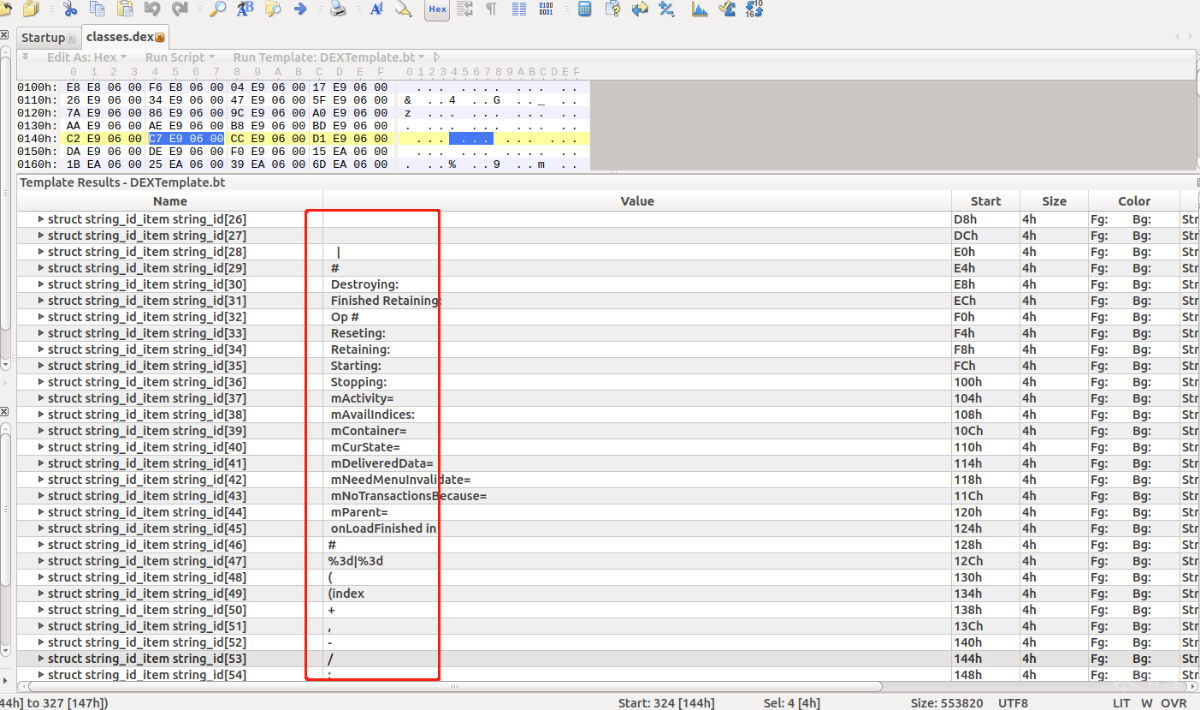
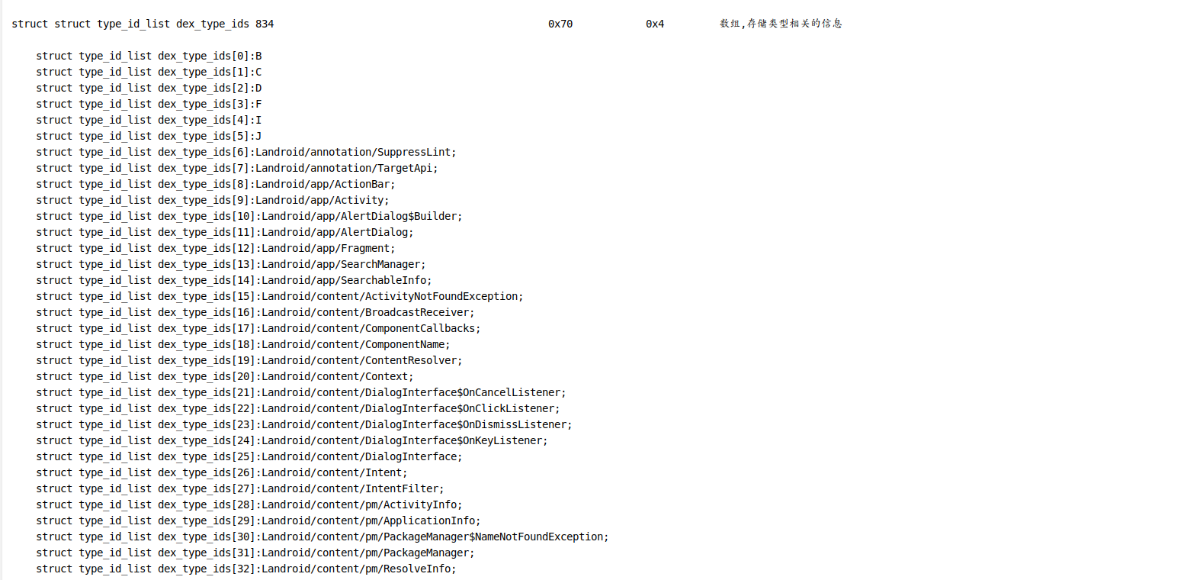
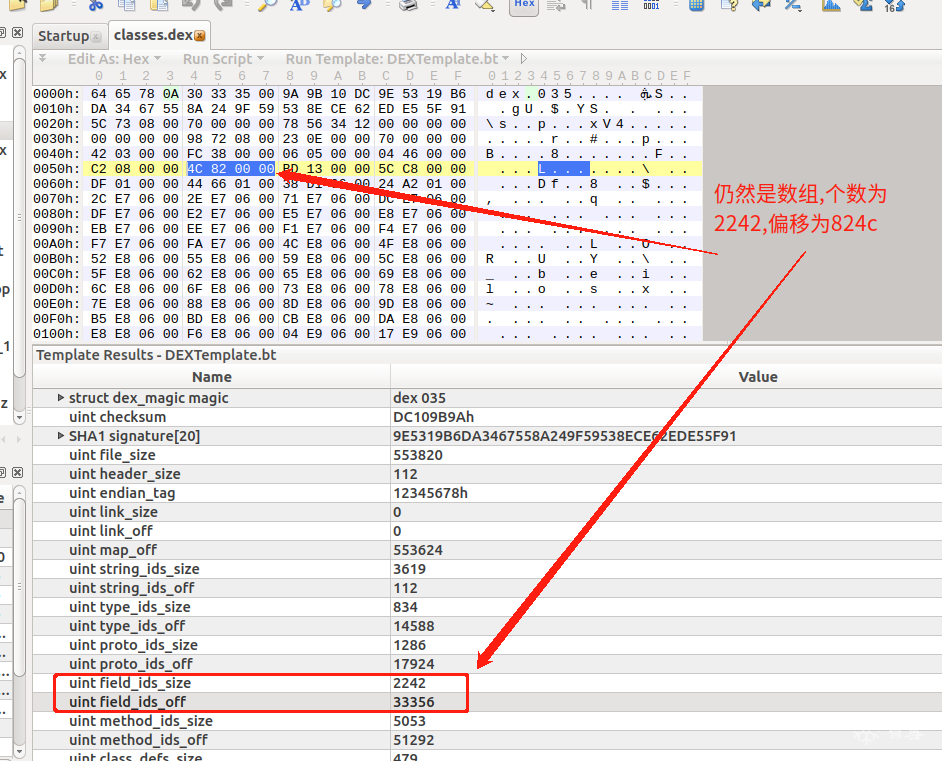



 不错,设置想打个赏
不错,设置想打个赏




