本人使用AI逆向和AI开发已经两年时间(目前是在做Agent开发),从纯粹网页时代的GPT辅助逆向到Claude3.5,到后面的AI爆发时代的GLM5.1,Claude4.7等等。看到很多人用ai逆向的思路和手法还是过于局限和原始(纯粹的流式对话)。想分享一些新思路。作者本身是做算法逆向还原,所以文章就以我自己的方向为主进行抛砖引玉。如何高效的逆向。(本文章零AI注水请放心食用,除开绘图使用了AI)
在AI逆向中结合经验我认为存在一下几个问题:
这几个问题也是苦恼我很久了。结合总结了一套方法:
基于上面思考我设计了一套逆向RE的工程框架,只要参与大型的逆向工程我会使用我这套框架来进行。设计图如下: 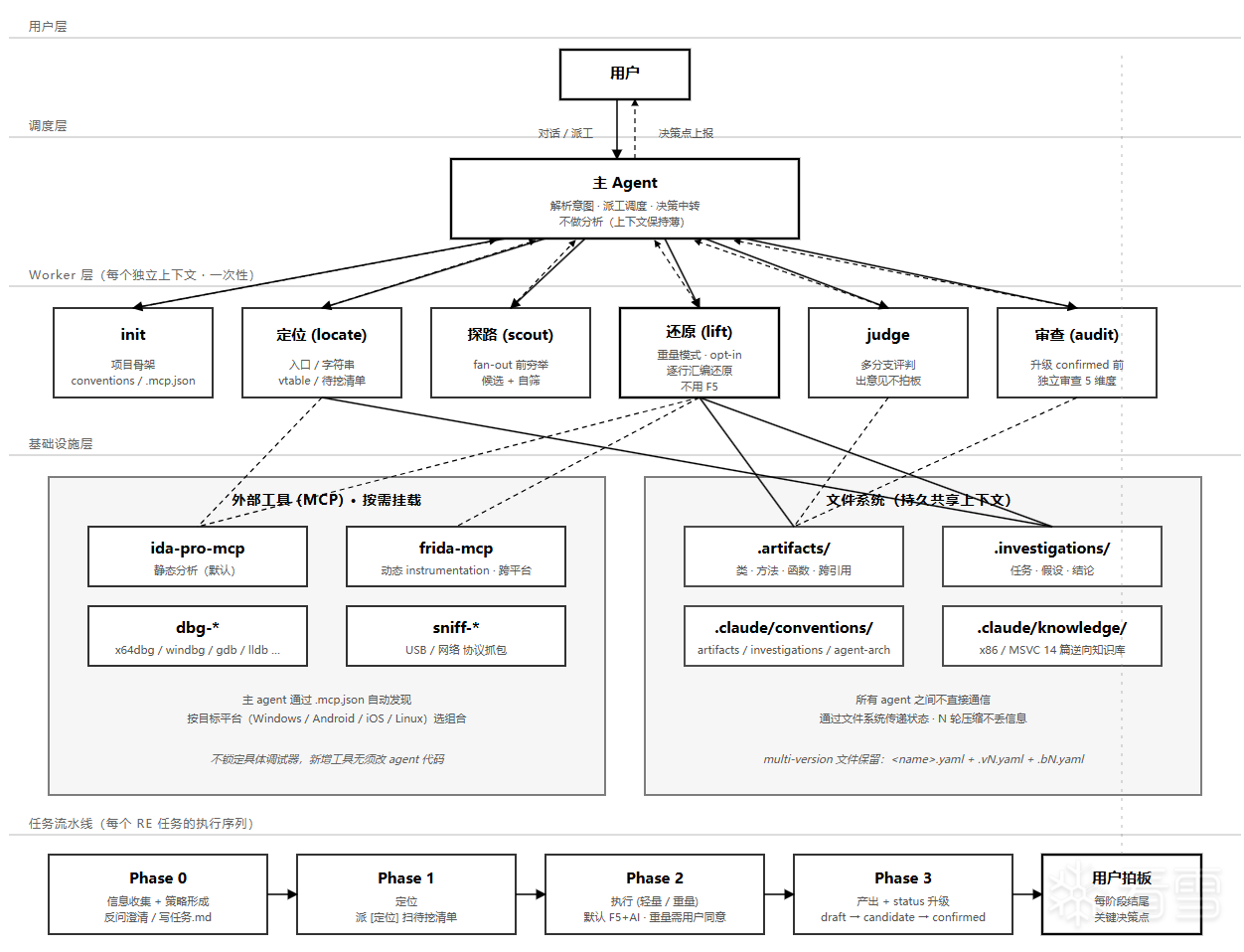 设计了一套多Agent的框架,由主脑来进行决策还任务的派发。主Agent直接与用户进行交互,拆解用户的语义分析,并且指挥下面的小弟干活。并且吧上下文管理,逆向分析,审查。拆分成几个Agent完成,如果说后续任务复杂度增加,已经继续增加我们的子agent,继续拆分细化任务。
设计了一套多Agent的框架,由主脑来进行决策还任务的派发。主Agent直接与用户进行交互,拆解用户的语义分析,并且指挥下面的小弟干活。并且吧上下文管理,逆向分析,审查。拆分成几个Agent完成,如果说后续任务复杂度增加,已经继续增加我们的子agent,继续拆分细化任务。 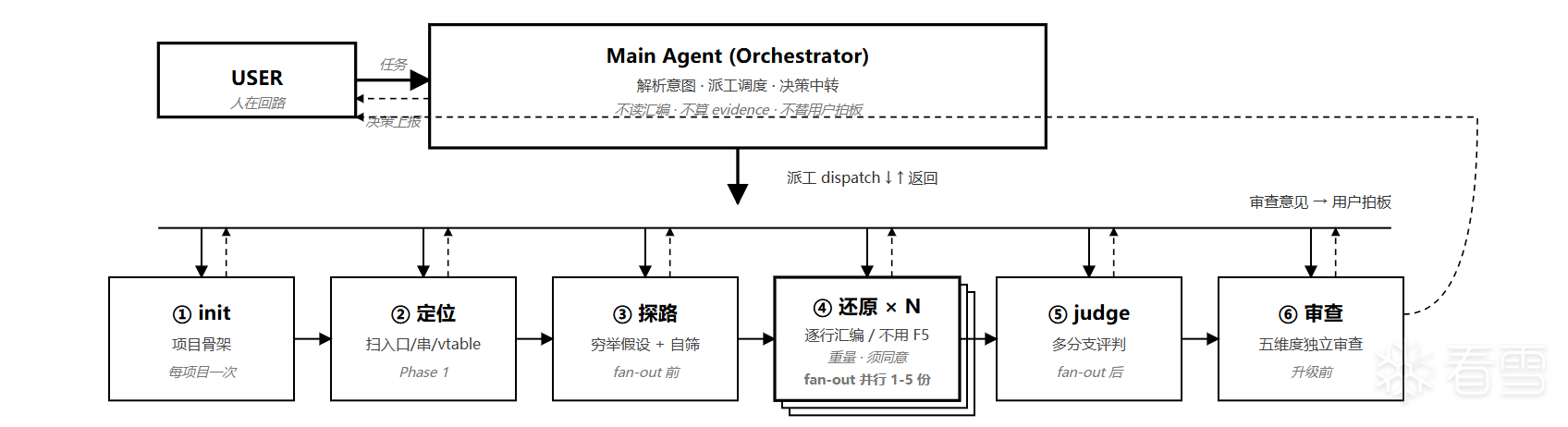
我吧Ai产物分成两个部分:
具体设计是这样的:
并且设计了如下几种文件格式用来存储我们的逆向中的信息:
由一个树形结构,一个主索引,我们的具体的逆向信息。一共有四类产物:class类文件,方法文件, 未归类函数或者说是面向过程中用到的。
类文件格式:
方法文件格式:
未归类函数:
这里介绍一下status 值,这个实际上就是我们的逆向的置信度,在AI逆向中,任何ai逆向的产出都是不可靠的,都是存在置信度的如果一旦100%信任你肯定会出大问题。所以我们需要给每个结果打上一个置信度,当有足够证据多维度验证后才能是可信的。否则agent在阅读这些信息的都是有一定的怀疑态度去对待。这个状态的更改是由审查agent负责 + 半人工的方式完成的。(这一步主要是解决幻觉问题)
所以设计了如下几个状态:
常见的流程是这样的:
最后给我们的不同的agent上不同的权限,但是confirmed一定要有人来审查,也就是意味着这个点完全没有问题。
在上面设计的情况下,我们是一个单一的一对一管理。但是我们知道逆向一般都是多个so或者dll进行的互相引入的,所以这种引入如何解决?用一个cross_refs文件来管理跨dll之间的关系表达:格式如下:
举例一下:
由于我们不可能一轮对话就可以吧一个任务完成,所以这里存在一个版本迭代问题。当我们逆向的第一版是这样的, 但是由于各种问题导致我们推翻了我们之前的分析过程和逆向过程。但是不确定第二个方向是对的情况下,就需要对版本进行管理。格式如下:
真实的情况是这样的:
通常笔者遇到的都是大型商业软件的逆向,所以遇到面向过程的的极少都是面向对象的设计模型。传统那几种吧。所以逆向到最后一定是一个类方法,虚方法等等。这里面就存在一个 最早期的函数到面向过程的转行问题,比如一个核心算法,他最后肯定是一个类,不是一个函数。在我们的上下文管理中就存在从函数状态的上下文到类对象的迁移过程。设计是这样的:
主要是做文件的迁移吧之前的旧文件删除,迁移到对应的类下面.
这个部分是非常杂的所以不能做那么精细化的区分。这里拿一个真实项目举例: 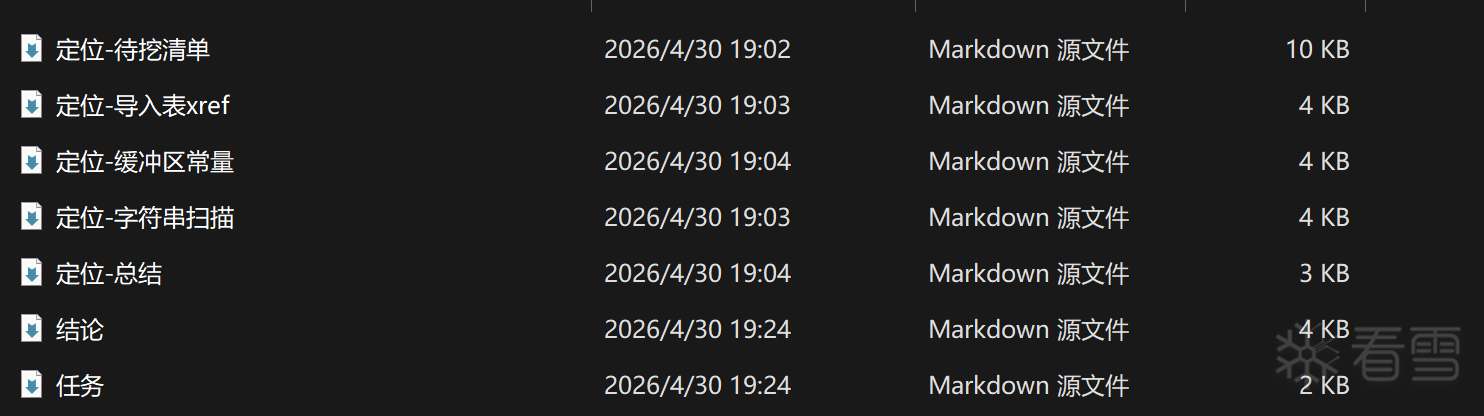 从任务出发到最后的定位总结分析 整套链路。设计如下:
从任务出发到最后的定位总结分析 整套链路。设计如下:
在说完我们的上下文管理后,讲一下在我自己的任务中存在的高精度还原问题。首先我蒸馏我自己,将所有的最基础的RE和编译原理进行蒸馏成一个知识库。 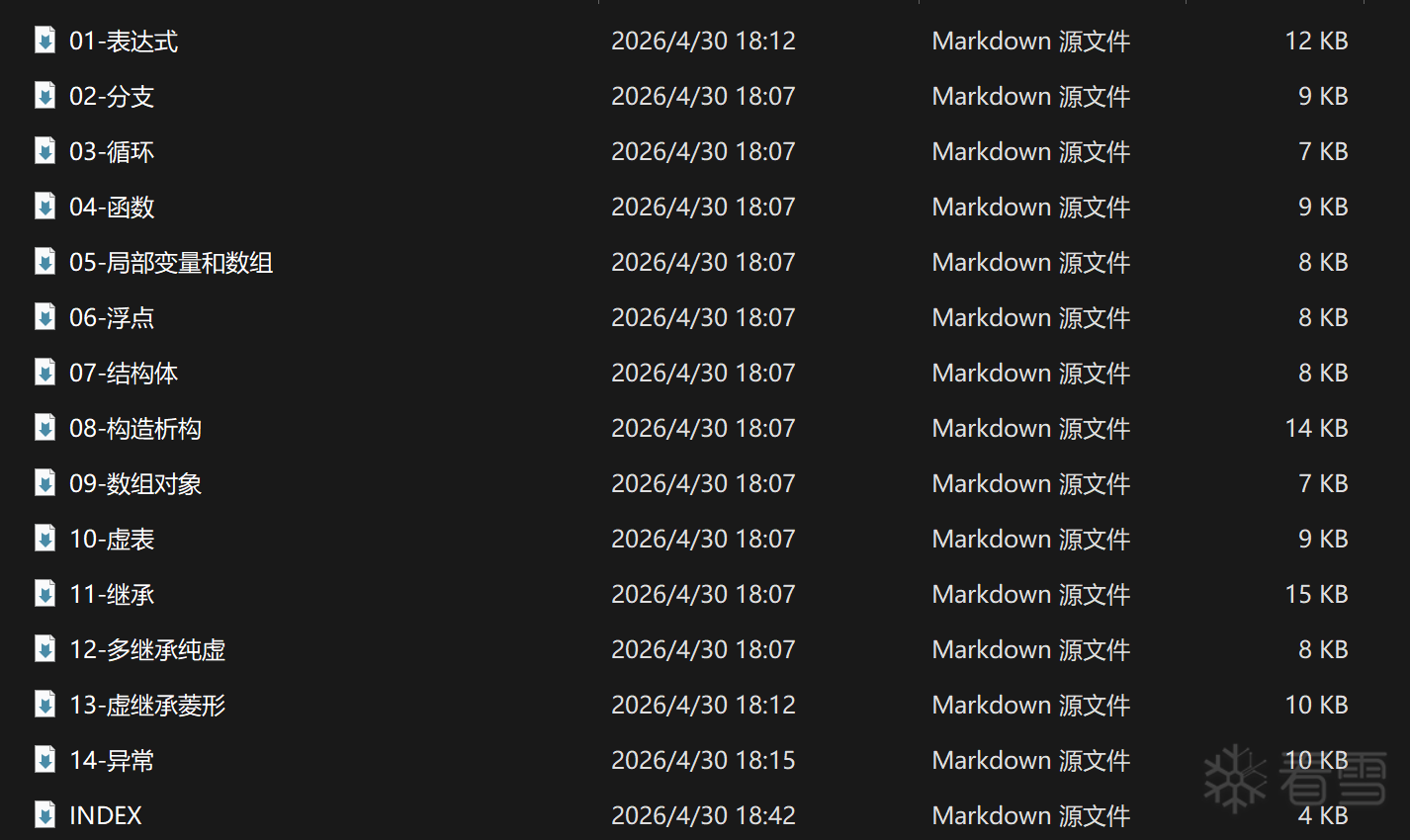 INDEX是整个知识库的索引目录,用来读取Agent遇到问题的时候所需要的知识。
INDEX是整个知识库的索引目录,用来读取Agent遇到问题的时候所需要的知识。
上面我说过AI是不懂逆向的,他懂的是F5以及汇编,不明白如何还原一个类或者一个算法。所以这里我整理了两个skills,一个是类分析和lift也就是我说的人肉f5.  这个位置就是我们需要技能,ai不会的,但是人为指点后就可以完成的事情。比如脱壳,去花等等。。。。
这个位置就是我们需要技能,ai不会的,但是人为指点后就可以完成的事情。比如脱壳,去花等等。。。。
在高精度的还原,我们人是通过汇编的骨架还原。流程如下:
这里产物一定是一个cpp文件,也就是对应上面的上下文的产物管理的部分。
由于我工作中大量需要设计类和对象的整个项目的工程化的评估,我需要有一个系统的评估技能。根据我自己的业务制作了一个Skills
这里我拿我之前网页AI时期的半古法分析的一个的帖子作为测试(Gtuner软件协议分析可以去看我自己的其他文章),看我这套东西是否能跑通。 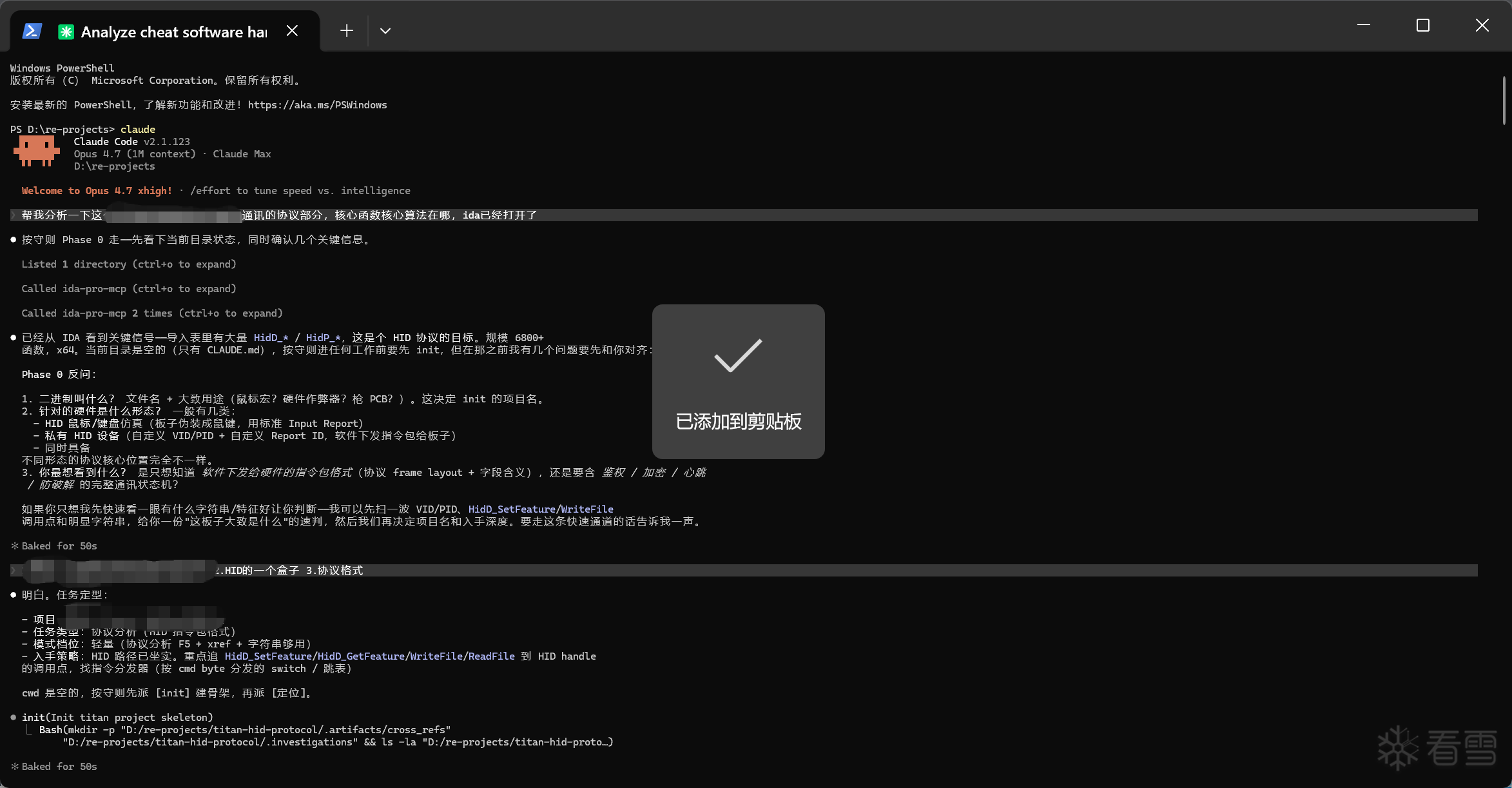
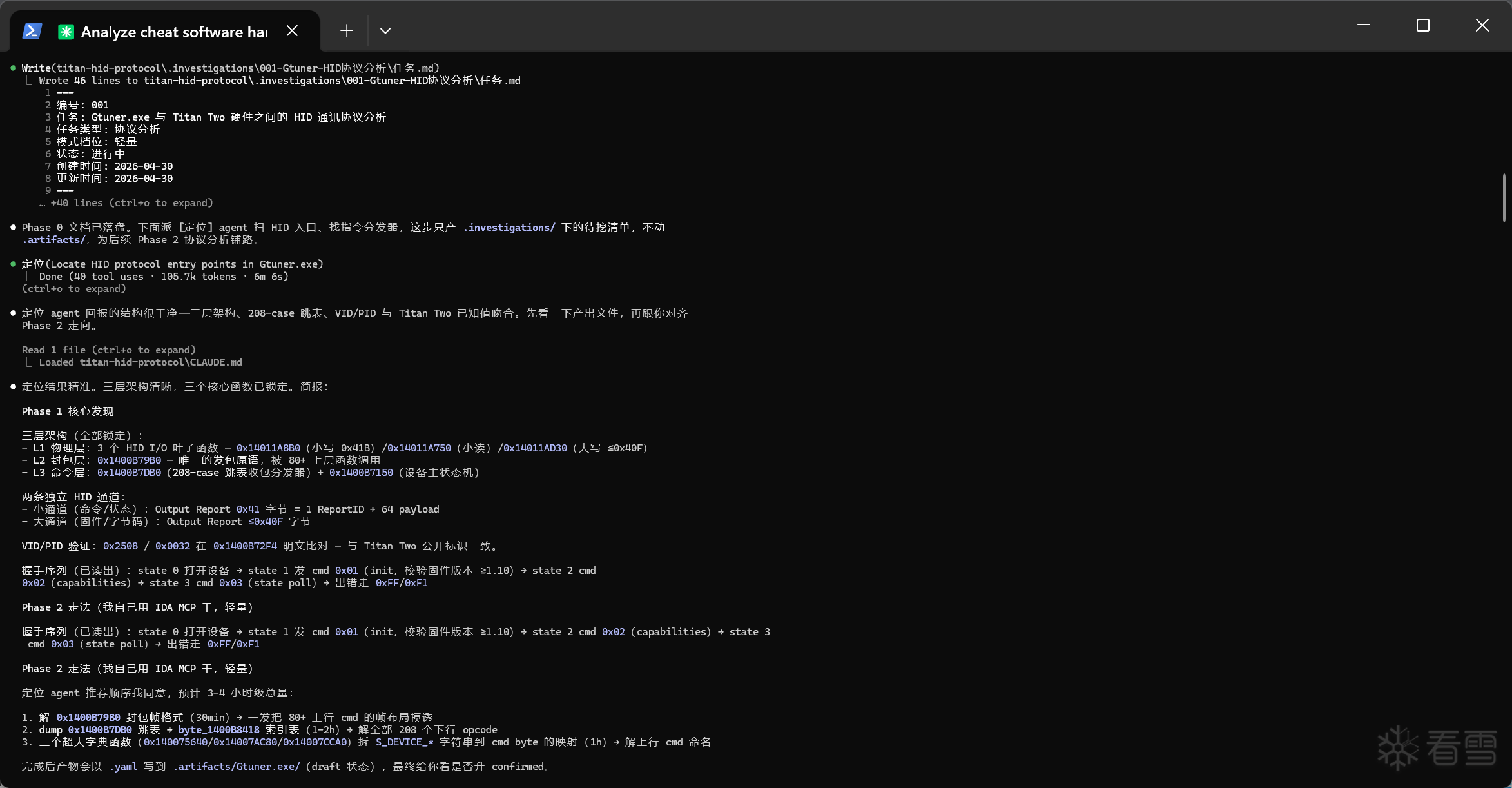
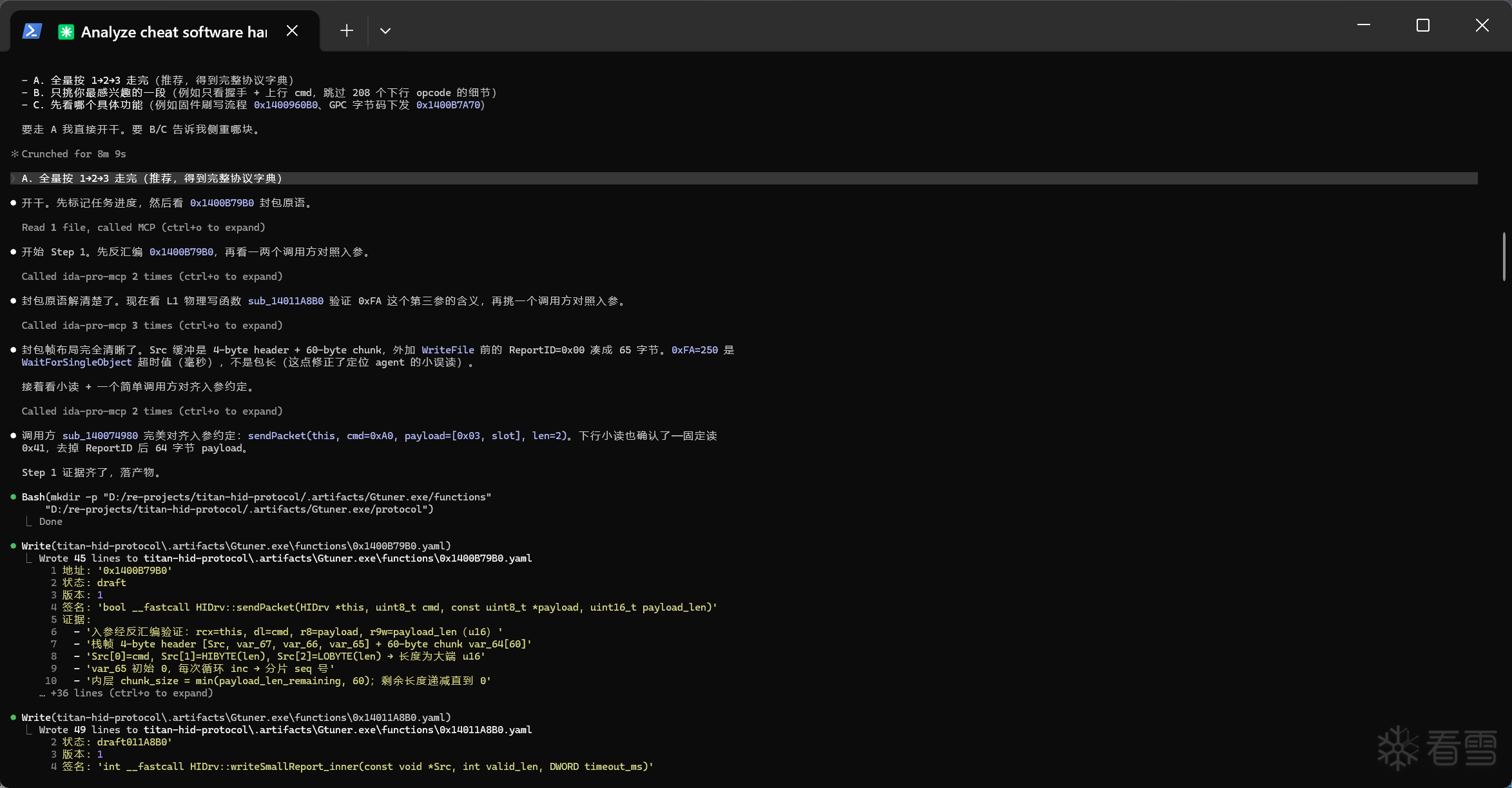
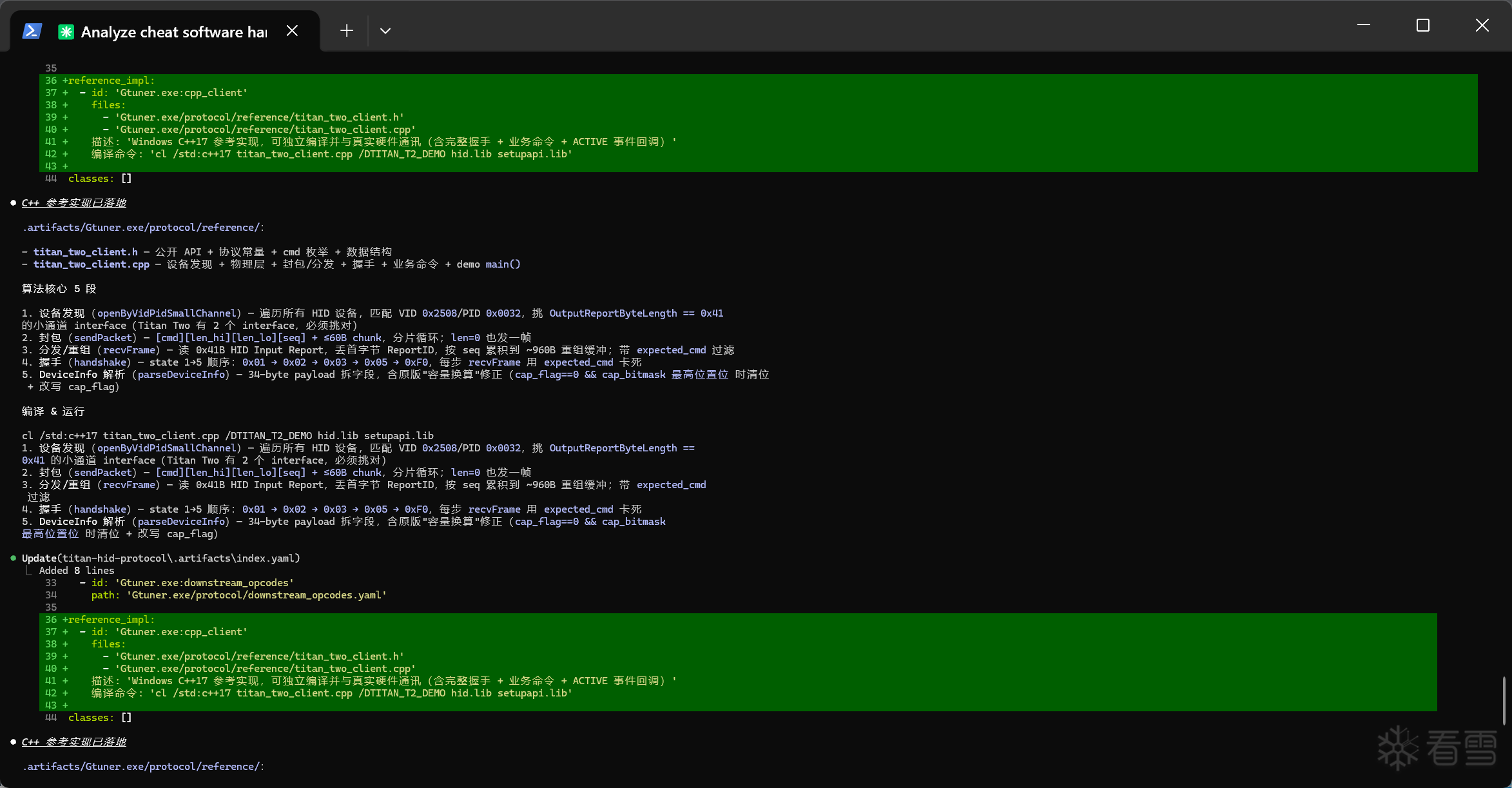 最后产物:
最后产物: 
 几乎是没用我多少时间,全程agent就自主完成了,中间打断了我四次(打了一把游戏agent就完成了)
几乎是没用我多少时间,全程agent就自主完成了,中间打断了我四次(打了一把游戏agent就完成了)
针对我自己的工作目前就这样设计的,目前还有动态调试的部分没有讲如何融入进来。这里主要是讲解设计,虽然我会把我的工程发到附件里面去,但是不推荐直接使用,可以利用我这种设计打造属于自己的"逆向工程sln"。这里推荐使用opencode,可以把主脑配置到deep seek v4,干活可以使用glm5.1,这样可以使用国产甚至是内网模型来完成工作,不再受制于claude 虽然它目前还是最强的。(感谢您看到这里了,如果觉得有帮助可以点个赞吗?对于有啥意见和感受都可以在评论区讨论)
| 字段 |
含义 |
类名 |
RTTI 真名优先,无 RTTI 用 Class_140xxxx 临时名 |
状态 |
status 值(见第五节) |
版本 |
时间线版本号 |
大小 |
sizeof(类) 字节数 |
vtable |
虚表地址 + 槽位数;无虚函数则 null |
父类 |
直接继承的基类列表,无继承则 [] |
字段 |
成员变量列表(偏移、类型、名字、初值、证据) |
方法清单 |
方法名引用列表(详情在 methods/<name>.yaml) |
| 字段 |
含义 |
类 |
所属类名 |
方法名 |
speak / Animal / ~Animal |
地址 |
函数地址(十六进制字符串) |
状态 |
status 值 |
版本 |
时间线版本号 |
签名 |
推断出的 C++ 签名 |
证据 |
判别依据列表 |
C 源码 |
反编译出的 C 代码(多行字符串) |
| 字段 |
含义 |
地址 |
函数地址 |
状态 |
status 值(一般是 draft 或 candidate) |
版本 |
时间线版本号 |
签名 |
推断出的签名(不确定时填 ???) |
证据 |
判别依据列表 |
C 源码 |
反编译出的 C 代码 |
| 状态 |
含义 |
谁能写 |
draft |
AI 单线程初稿,未经验证 |
worker |
wip |
正在分析中,尚未完成 |
worker |
candidate |
fan-out 候选 / judge 选中待审 |
worker / judge 选 |
confirmed |
已经过用户拍板的最终结论 |
仅用户 |
rejected |
经验证或拍板被驳回 |
judge / 审查 / 用户 |
superseded |
被新版本取代(历史归档常用) |
librarian / agent 升级新版本时 |
[培训]《冰与火的战歌:Windows内核攻防实战》!从零到实战,融合AI与Windows内核攻防全技术栈,打造具备自动化能力的内核开发高手。
最后于 2026-4-30 22:14
被BitWarden编辑
,原因:





