-
-
[原创] 浅谈梯度分析与权重编辑:以Qwen-3为例
-
发表于: 12小时前 356
-

早在2024年,便有学者发现LLMs的拒绝回答往往由单一梯度方向介导。
作为一篇社区博客,本文将谈论如何让Qwen3-4B-Instruct-2507拒绝回答所有问题,而不是如何让Qwen3-4B-Instruct-2507回答所有问题,无论合法与否,以避免不必要的副面影响(拒绝回答一个问题几乎总是没有负面影响的)。请勿恶意修改梯度方向,避免模型输出不恰当的内容。
那么,闲话休提,让我们开始吧。
在开始分析拒绝向量的内容前,我们必须先明确拒绝向量的位置。  Qwen3-4B-Instruct-2507的模型架构相对简单,主体(去掉嵌入等)由36层Qwen-3 decoder layer组成;每个Decoder layer的结构都由一个注意力块(Attention Block)和一个MLP块组成;总体如上图所示。其中,红线代表残差(Residual);蓝块为最后的权重块。
Qwen3-4B-Instruct-2507的模型架构相对简单,主体(去掉嵌入等)由36层Qwen-3 decoder layer组成;每个Decoder layer的结构都由一个注意力块(Attention Block)和一个MLP块组成;总体如上图所示。其中,红线代表残差(Residual);蓝块为最后的权重块。
那么在此即可讨论可行的干预点:首先,对于此模型而言,干预注意力是几乎不可行的,原因有二:其一,模型采用了块间残差而非层间残差。这意味着残差流对MLP产生的影响增强了:传统的MLP块的输入为注意力的输出,意味着MLP看不到没有被注意到的内容;因此只要让MLP看不到内容的应拒绝性,MLP就无从产生拒绝的意向。但是在这里,MLP可以绕过注意力机制看到输入隐状态(Input Hidden States)的残差,导致哪怕干预了注意力,MLP也会产生拒绝方向。其二,其MLP块本身也类似于朴素注意力。虽然经过了激活而不是softmax,门投影仍然可以被视为某种意义上的注意力;至少它也会产生类似于Gate的效果。因此,其内部权重也不会完全依赖传统注意力。
类似地,会有两张可行的编辑思路。其中一种是干预残差;最著名的使用者为(huihui_ai);另一种思路为利用对块的补偿;最著名的使用者为(p-e-w)。这里,我们为了修订后的模型可以被转为gguf等,选择第二种思路。除此之外,与heretic不同,为了更完整地展示LoRA的原理,我们不使用peft库,而是直接计算r=1时LoRA的每个权重并进行合并。这不是规范操作,但是我认为这样对展示方法有帮助。我们将从输出状态叠加残差前,也就是第二个块的下投影的输出中(图中蓝色的Down Projection块)分析拒绝向量并进行编辑;亦因此,我们将其定义为拒绝向量的位置。
在确定了拒绝向量的位置后,我们需要开始观测拒绝向量的方向。利用pytorch的hook机制,我们可以轻易地获取其下投影(Down Projection,代码中记dp)和残差(Residual,代码中记res)。
我准备了一个非常小的应拒绝提问与不应拒绝的提问列表,并计算了它们的dp_t的平均数。不过,一个有成百上千个维度的向量难以可视化,让我们使用PCA:


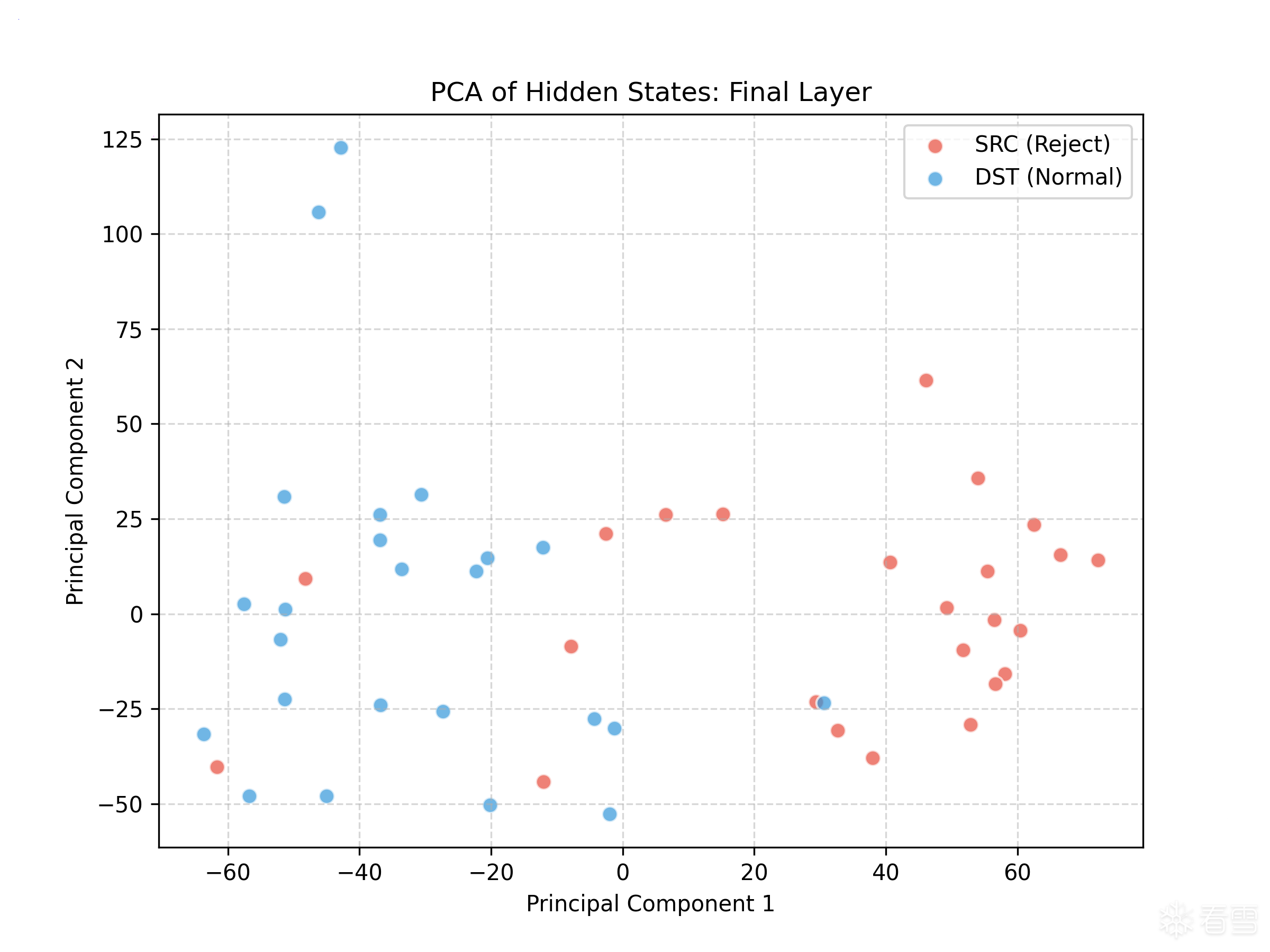
从图中可以看出:
除此之外,我们确认了,确实可以找到一个单一的线性地方向,使得这些样本被合并。
我们知道,LoRA的公式是:
h=W0x+ΔWx=W0x+BAx
其中,W0∈Rd×k 是预训练模型的原始权重,B∈Rd×r 和 A∈Rr×k 是可训练的低秩矩阵,秩 r≪min(d,k)。
从上图中不难一眼看出,r=1时即可完成任务。我们希望ΔWsdp=dres−sres,使用最小二乘 u=SssSdd−Ssd2Sddsdp−Ssdddp,记ΔW=v⊗(uW),即可完成构造;数学证明从略;代码上看,就是
(嗯,我也想过怎么避开公式说明这些...可能是不太行的)
那么就完成了...吗?
刚开始我们提到,Qwen3-4B-Instruct-2507有36层。
一个很细微但是重要的问题是:我们要编辑哪个/哪些层呢?
瞎猜吗 当然也可以 但是如果我不想猜呢
赞赏
|
|
|---|---|
|
|
|




