一.分析程序
IDA分析程序:
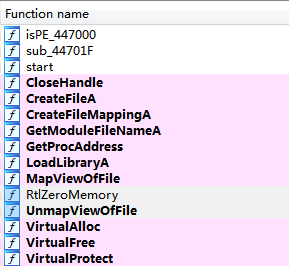
只有这么几个函数,好可怕,肯定是加壳了。
二.壳流程

主要算法1,赋值原区段内容异或解密

壳中主要算法2,加载API,修复导入表,请注意图中的API,~^o^~
整个壳的流程也比较简单,只要一路往下走,打死不回头,很快就能找到跳到oep的magic jmp:
004473A8 FFE0 JMP NEAR EAX
恩,接着想脱壳的就可以脱了,win7 由于某些原因没有成功,不过也dump了一份供IDA分析。
三.胜利曙光-->黎明的黑暗
用IDA分析dump文件,分分钟找到关键点:
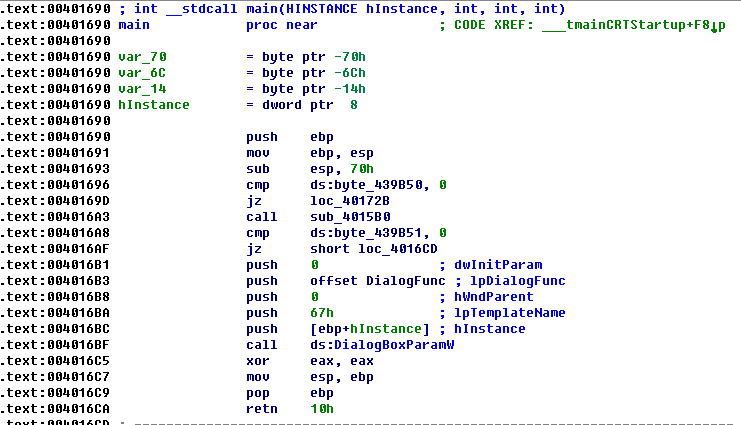
跟进DialogFunc:

流程是不是很清晰
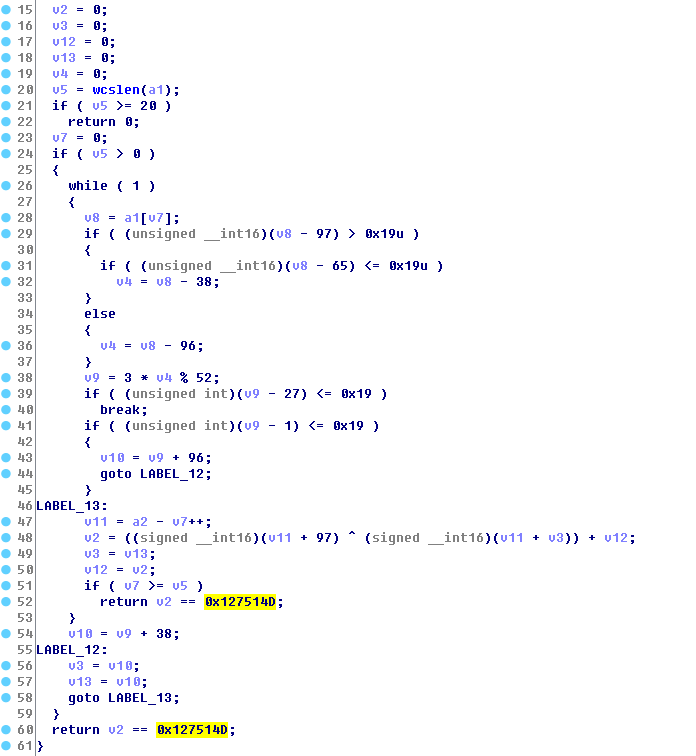
关键call是不是也很简单。。。。。。。。。。。。。。。。
然而算了两个小时也并不还原。
这一切都是假的。。。。。。。。
四.反调试
接着回头从脱壳开始,一步一步跟踪,发现了很多有意思的API
CreateToolhelp32Snapshot
WaitForDebugEvent
SetThreadContext
WriteProcessMemory
从新梳理流程,发现main函数有猫腻:
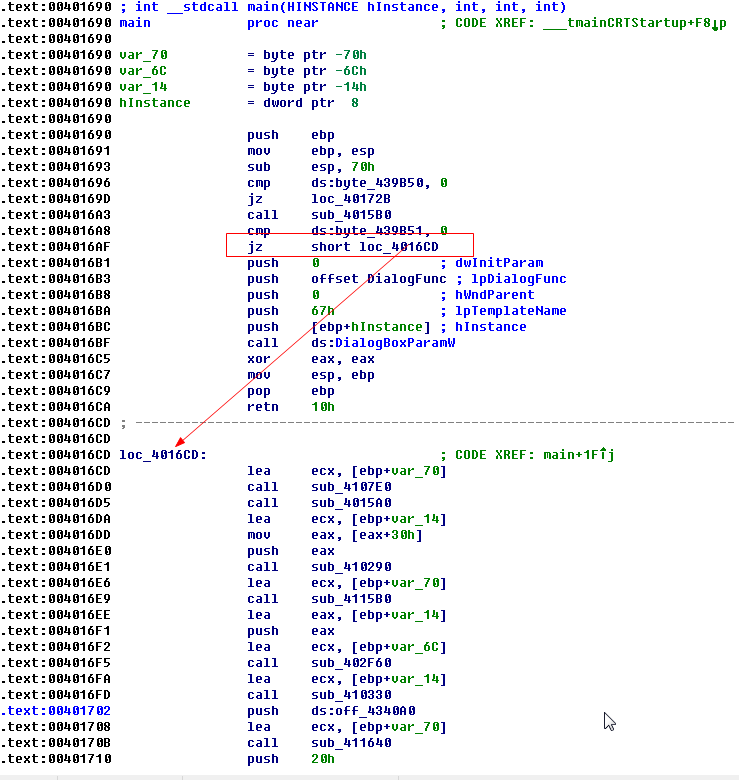
发现某些条件下竟然可以跳过产生对话框,what fuck this,那我们看到的对话框是什么???
接着详细跟踪。。。
sub_4015B0 提权
这部分后续更新。。。。。。20170623更新
sub_401480 遍历进程,判断父进程:

判断是否为explorer 或者cmd,之后直接把OD改成explorer.exe调试。
其他反调试未留意。。。。。
五.正确流程
1.跳过创建对话框
SEG001:004016AF 74 1C jz short loc_4016CD
2.用自身程序创建一个进程,并与之交互
SEG001:0040170B E8 30 FF 00 00 call sub_411640
sub_410A20
下断点WriteProcessMemory,ReadProcessMemory
可发现以下信息:
0248FCC8 00402013 /CALL 到 WriteProcessMemory 来自 crakeme.00402011
0248FCCC 00000294 |hProcess = 00000294 (window)
0248FCD0 004017BD |Address = 0x4017BD
0248FCD4 0248FE54 |Buffer = 0248FE54
0248FCD8 00000002 |BytesToWrite = 0x2
0248FCDC 0248FE3C \pBytesWritten = 0248FE3C
0248FCE0 74785F70 JMP 到 KernelBa.GetLastError
0248FE54 90 90 悙$
0248FCC8 0040209C /CALL 到 WriteProcessMemory 来自 crakeme.0040209A
0248FCCC 00000294 |hProcess = 00000294 (window)
0248FCD0 00401A43 |Address = 0x401A43
0248FCD4 0248FE3C |Buffer = 0248FE3C
0248FCD8 00000005 |BytesToWrite = 0x5
0248FCDC 0248FE54 \pBytesWritten = 0248FE54
0248FE3C E9 BB 08 00 00 榛�...
修改了程序中的两个地方,地址在我们发现的假的流程中:
这段代码主要作用是修改这两个地方:
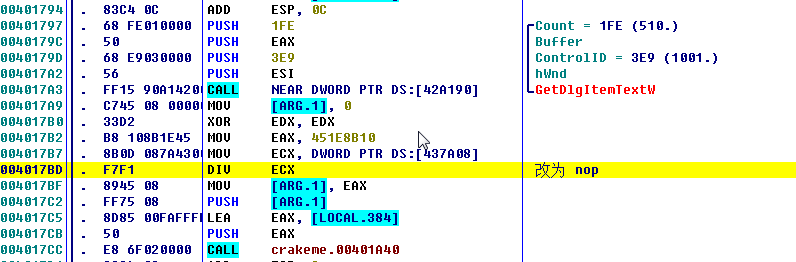

修改后:

这才是正确的流程,发现了这个接下来步入正途了。
接下来的函数F5的代码也超长,我也不知道作者高了什么操作。。。。。。。。。。。
不过都是浮云,直接对我们输入的注册码下内存访问断点,可以到找到如下关键点:
if ( string2Hex_401BC0(a1, (int *)&v162) )
if ( string2Hex_401B10(a1 + 16, &v160)
string2Hex_401BC0 将我们输入的前八个字符转换成16进制形式 比如 输入“12345678” 转换之后 0x12345678 转换后保存在v162 函数中判断必须是数字加大写字母,大写字母超过F会被转换
string2Hex_401B10(a1 + 16, &v160)将我们输入的第九第十个字符转换成16进制形式 比如 输入“1e” 转换之后 0x1e 转换后保存在v160 函数中判断必须是数字加大写字母,大写字母超过F会被转换
#这一段主要是解密加判断比较
v64_i = 0;
if ( v62 & 0xFFFFFFFC )
{
v65 = v162;//我们输入的前八个字符转换成16进制形式
v66 = v161;
v67 = 0x1010101 * v160; //我们输入的第九第十个字符
do
{
*(_DWORD *)(v66 + 4 * v64_i) = (v67+ *(_DWORD *)(v66 + 4 * v64_i)) ^ (v64_i + v65);
++v64_i;
}
while ( v64_i < v129 >> 2 );
v63 = a1;
}
v68 = (int (__cdecl *)(int *, signed int, int, char *))v161;
v69 = 0;
while ( byte_4340B0[v69] == *(&byte_4340B0[v69] + v161 - (unsigned int)byte_4340B0) )
{
if ( (unsigned int)++v69 >= 0x60 )
........
}代码基本类似以下python代码:
#程序中的算法
#num_8 //我们输入的前八个字符转换成16进制形式
#byte9 //我们输入的第九第十个字符
def encode(num_8,byte9):
tepList=[]
esi=byte9*0x1010101
for i,x in enumerate(enCodeList):
tmp=x+esi
tmp=tmp^(i+num_8)
tepList.append(tmp)
print tepList
for i in range(len(enCodeList)):
print hex(tepList[i]),hex(deCodeList[i]),tepList[i]==deCodeList[i]
最后比较的数组在地址4340B0处,现成的0x60 字节。
有了上边的信息,我们就可以求出前10位:
import base64
#pip install pyDes
import pyDes
import binascii
enCodeList=[0x83f08ea7, 0x3f0fba29, 0xe747e97c, 0x93d03647, 0xec72cd2c, 0x93c0ba2e, 0x90a578a3, 0x2a40ba2f, 0xdb3ff233, 0x9031fb09, 0xd1477258, 0x905e3dac, 0xab817c35, 0x6bd43434, 0xc49e84e4, 0x83b426af,0x51c0ba3a, 0x280080b8, 0x93be3ff3, 0x8e36ba3b, 0xe9c0ba3c, 0x93c0ba29, 0x93c0b2c5, 0x1680cd3f]
#4340B0
deCodeList=[0x1070ec81, 0x55530000, 0xbc8b5756, 0x00108424, 0xbbf63300, 0x00000001, 0x0725c68b, 0x79800000, 0xc8834805, 0x07b140f8, 0xc68bc82a, 0x07e28399, 0xf8c1c203, 0x38148a03, 0xd322fad2, 0x10349488,
0x46000002, 0x7c40fe83, 0x0002bdcf, 0x05ba0000, 0xbe000000, 0x00000014, 0x000008b9, 0x8dc03300]
def baopo(byte9):
#print '#'*5,"index:",byte9,'#'*10
begin=0
esi=byte9*0x1010101
for i,x in enumerate(enCodeList):
tmp=(x+esi)&0xFFFFFFFF
num_8=(tmp^deCodeList[i])-i
#print tmp,num_8
if i==0:
begin=num_8
else:
if begin!=num_8:
break
#print i,len(enCodeList)
return i==(len(enCodeList)-1)
#计算前10字节
def find_key_left_10():
for i in range(0,256):
if baopo(i):
key=hex((((i*0x1010101)+enCodeList[0])&0xFFFFFFFF)^deCodeList[0]).upper()[2:-1]+hex(i).upper()[2:]
#print "byte9:",hex(i),"num_8",hex((((i*0x1010101)+enCodeList[0])&0xFFFFFFFF)^deCodeList[0])
#raw_input("find:")
return key
#out:75A29C09E1n.最后的战役
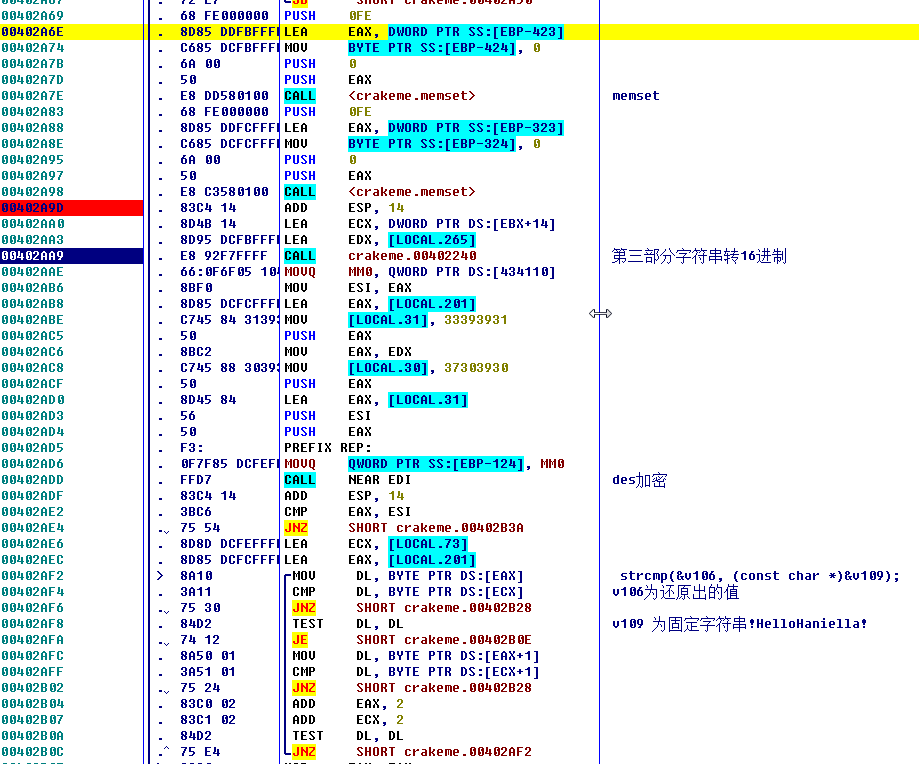
就是这段,先把10位之后的转成16进制,然后进行des解密与固定字符串比较。
des识别:

直接搜索这部分常量就可以知道是des。
DES是个蛋疼的密码学算法,模式众多,还有不少参数,卡着卡了很久。。
DES还原第一步,找到模式,找到IV
#测试des 算法中的iv值
def test_iv():
'''
[in] 0018EF5C 3F 9C 81 2B 33 6F 32 52 BB F5 94 39 BC CA 53 C5 ?渷+3o2R货?际S?
00402ADD FFD7 CALL NEAR EDI
[out] 0018F05C 8B E2 CF C6 C6 C5 E2 CB FB 5F 4E ED F5 A4 B9 F9 嬧掀婆馑鸰N眭す?
index 170 decode 8BE2CFC6C6C5E2CB6E69656C6C6121
'''
enData=[0x3f, 0x9c, 0x81, 0x2b, 0x33, 0x6f, 0x32, 0x52, 0xbb, 0xf5, 0x94, 0x39, 0xbc, 0xca, 0x53, 0xc5]
text=""
for x in enData:
text+=chr(x)
for i in range(0,256):
k = pyDes.des("19930907",pyDes.CBC, chr(i)*8, pad=None,padmode=pyDes.PAD_PKCS5)
d=k.decrypt(text)
print "index",i,"decode",binascii.hexlify(d).upper()根据我们的输入和程序的输出,变化加密模式[CBC,EBC]和IV的值,看那个输出和程序计算结果一只,最后发现是170
DES还原第二步,又卡了很久,发现两段要分开计算:
#计算des密文
def key2():
data = "!HelloHaniella!"+chr(0)
iv=chr(170)*8
key='19930907'
desObj = pyDes.des(key,pyDes.CBC, iv, pad=None,padmode=pyDes.PAD_PKCS5)
d=desObj.encrypt(data[0:8])
key_part_1=binascii.hexlify(d).upper()
#print "first",key_part_1
desObj1 = pyDes.des(key,pyDes.CBC, iv, pad=None,padmode=pyDes.PAD_PKCS5)
d1=desObj1.encrypt(data[8:])
key_part_2=binascii.hexlify(d1).upper()
#print "second",key_part_2
#print key_part_1[0:16]+key_part_2[0:16]
return key_part_1[0:16]+key_part_2[0:16]
完整脚本:
import base64
#pip install pyDes
import pyDes
import binascii
enCodeList=[0x83f08ea7, 0x3f0fba29, 0xe747e97c, 0x93d03647, 0xec72cd2c, 0x93c0ba2e, 0x90a578a3, 0x2a40ba2f, 0xdb3ff233, 0x9031fb09, 0xd1477258, 0x905e3dac, 0xab817c35, 0x6bd43434, 0xc49e84e4, 0x83b426af,
0x51c0ba3a, 0x280080b8, 0x93be3ff3, 0x8e36ba3b, 0xe9c0ba3c, 0x93c0ba29, 0x93c0b2c5, 0x1680cd3f]
deCodeList=[0x1070ec81, 0x55530000, 0xbc8b5756, 0x00108424, 0xbbf63300, 0x00000001, 0x0725c68b, 0x79800000, 0xc8834805, 0x07b140f8, 0xc68bc82a, 0x07e28399, 0xf8c1c203, 0x38148a03, 0xd322fad2, 0x10349488,
0x46000002, 0x7c40fe83, 0x0002bdcf, 0x05ba0000, 0xbe000000, 0x00000014, 0x000008b9, 0x8dc03300]
def baopo(byte9):
#print '#'*5,"index:",byte9,'#'*10
begin=0
esi=byte9*0x1010101
for i,x in enumerate(enCodeList):
tmp=(x+esi)&0xFFFFFFFF
num_8=(tmp^deCodeList[i])-i
#print tmp,num_8
if i==0:
begin=num_8
else:
if begin!=num_8:
break
#print i,len(enCodeList)
return i==(len(enCodeList)-1)
#计算前10字节
def find_key_left_10():
for i in range(0,256):
if baopo(i):
key=hex((((i*0x1010101)+enCodeList[0])&0xFFFFFFFF)^deCodeList[0]).upper()[2:-1]+hex(i).upper()[2:]
#print "byte9:",hex(i),"num_8",hex((((i*0x1010101)+enCodeList[0])&0xFFFFFFFF)^deCodeList[0])
#raw_input("find:")
return key
print find_key_left_10()
#程序中的算法
def encode(num_8,byte9):
tepList=[]
esi=byte9*0x1010101
for i,x in enumerate(enCodeList):
tmp=x+esi
tmp=tmp^(i+num_8)
tepList.append(tmp)
print tepList
for i in range(len(enCodeList)):
print hex(tepList[i]),hex(deCodeList[i]),tepList[i]==deCodeList[i]
#测试des 算法中的iv值
def test_iv():
'''
[in] 0018EF5C 3F 9C 81 2B 33 6F 32 52 BB F5 94 39 BC CA 53 C5 ?渷+3o2R货?际S?
00402ADD FFD7 CALL NEAR EDI
[out] 0018F05C 8B E2 CF C6 C6 C5 E2 CB FB 5F 4E ED F5 A4 B9 F9 嬧掀婆馑鸰N眭す?
index 170 decode 8BE2CFC6C6C5E2CB6E69656C6C6121
'''
enData=[0x3f, 0x9c, 0x81, 0x2b, 0x33, 0x6f, 0x32, 0x52, 0xbb, 0xf5, 0x94, 0x39, 0xbc, 0xca, 0x53, 0xc5]
text=""
for x in enData:
text+=chr(x)
for i in range(0,256):
k = pyDes.des("19930907",pyDes.CBC, chr(i)*8, pad=None,padmode=pyDes.PAD_PKCS5)
d=k.decrypt(text)
print "index",i,"decode",binascii.hexlify(d).upper()
#计算des密文
def key2():
data = "!HelloHaniella!"+chr(0)
iv=chr(170)*8
key='19930907'
desObj = pyDes.des(key,pyDes.CBC, iv, pad=None,padmode=pyDes.PAD_PKCS5)
d=desObj.encrypt(data[0:8])
key_part_1=binascii.hexlify(d).upper()
#print "first",key_part_1
desObj1 = pyDes.des(key,pyDes.CBC, iv, pad=None,padmode=pyDes.PAD_PKCS5)
d1=desObj1.encrypt(data[8:])
key_part_2=binascii.hexlify(d1).upper()
#print "second",key_part_2
#print key_part_1[0:16]+key_part_2[0:16]
return key_part_1[0:16]+key_part_2[0:16]
def full_Key():
print "Key: ",find_key_left_10()+key2()
full_Key()
Key: 75A29C09E180217C048420956C15DA309FF2B69170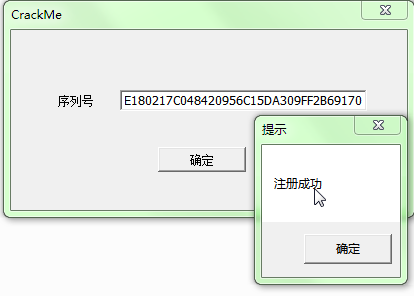
[CTF入门培训]顶尖高校博士及硕士团队亲授《30小时教你玩转CTF》,视频+靶场+题目!助力进入CTF世界






